Ethical Considerations and Model Interpretation in AI: Ensuring Trust and Transparency
Table of Contents
2. RFP: xAI
3. Context: Change Complexity
Whether humans are directly using machine learning classifiers as tools, or are deploying models within other products, a vital concern remains: if the users do not trust a model or a prediction, they will not use it. It is important to differentiate between two different (but related) definitions of trust: (1) trusting a prediction, i.e. whether a user trusts an individual prediction sufficiently to take some action based on it, and (2) trusting a model, i.e. whether the user trusts a model to behave in reasonable ways if deployed.
There are many steps involved from prepping data, choosing algorithms, building, training, and deploying models … and iterating over and over again.
- Enterprise AI Guide, AWS
However, the harsh reality is that without a reasonable understanding of how machine learning models or the data science pipeline works, real-world projects rarely succeed.
In this paper, we argue that ML systems have a special capacity for incurring technical debt, because they have all of the maintenance problems of traditional code plus an additional set of ML-specific issues. This debt may be difficult to detect because it exists at the system level rather than the code level. Traditional abstractions and boundaries may be subtly corrupted or invalidated by the fact that data influences ML system behavior. Typical methods for paying down code level technical debt are not sufficient to address ML-specific technical debt at the system level.
Quality depends not just on code, but also on data, tuning, regular updates, and retraining.
Second, the idea that you can audit and understand decision-making in existing systems or organisations is true in theory but flawed in practice. It is not at all easy to audit how a decision is taken in a large organisation.
4. Considerations
- Model Analysis
- ML Pipelines
- Interfaces: Preconditions and Postconditions
- Workflow Management
- Baselines and QA
- Deployments and Versioning
- Causality
5. Tools
- Seaborn
- LIME https://homes.cs.washington.edu/~marcotcr/aaai18.pdf
- Yellowbrick http://joss.theoj.org/papers/10.21105/joss.01075
6. Resources
8. Interpretability and fairness pipeline
// Interpretability + fairness pipeline -- explainability on one side, // bias audit on the other, both gating a human-reviewed deployment. digraph interpretability_stack { rankdir=LR; graph [bgcolor="white", fontname="Helvetica", fontsize=11, pad="0.3", nodesep="0.3", ranksep="0.45"]; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10, fillcolor="#dbeafe", color="#888", fontcolor="#555"]; edge [color="#888", fontcolor="#555"]; // Inputs train [label="Training data\n+ labels", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; model [label="Trained model\n(black box)", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; train -> model [label="fit", fontsize=9]; // Explainability cluster subgraph cluster_explain { label="Explainability"; labeljust="l"; color="#15803d"; fontcolor="#15803d"; style="rounded"; shap [label="SHAP\n(TreeExplainer,\nDeepExplainer)", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; lime [label="LIME\n(local surrogates)", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; ig [label="Integrated\ngradients\n(Captum)", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; cf [label="Counterfactuals\n(DiCE, Alibi)", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; explanation [label="Local + global\nexplanations", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; shap -> explanation; lime -> explanation; ig -> explanation; cf -> explanation; } // Fairness cluster subgraph cluster_fair { label="Fairness audit"; labeljust="l"; color="#b91c1c"; fontcolor="#b91c1c"; style="rounded"; fairlearn [label="Fairlearn\n(Microsoft)", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; aequitas [label="Aequitas\n(Univ. of Chicago)", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; metrics [label="Group metrics\n(demographic parity,\nequalized odds)", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; bias_report [label="Bias report", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; fairlearn -> metrics -> bias_report; aequitas -> metrics; } // Model fans out into both review passes model -> shap; model -> lime; model -> ig; model -> cf; model -> fairlearn; model -> aequitas; // Human reviewer gate reviewer [label="Human reviewer\n(domain expert\n+ compliance)", fillcolor="#fef9c3", color="#a16207", fontcolor="#a16207"]; explanation -> reviewer; bias_report -> reviewer; // Production deploy [label="Production\ndeployment", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; reviewer -> deploy [label="approve", fontsize=9, color="#6b21a8"]; // Feedback loop back to retraining deploy -> train [label="drift / new labels", style=dashed, color="#888", constraint=false]; }
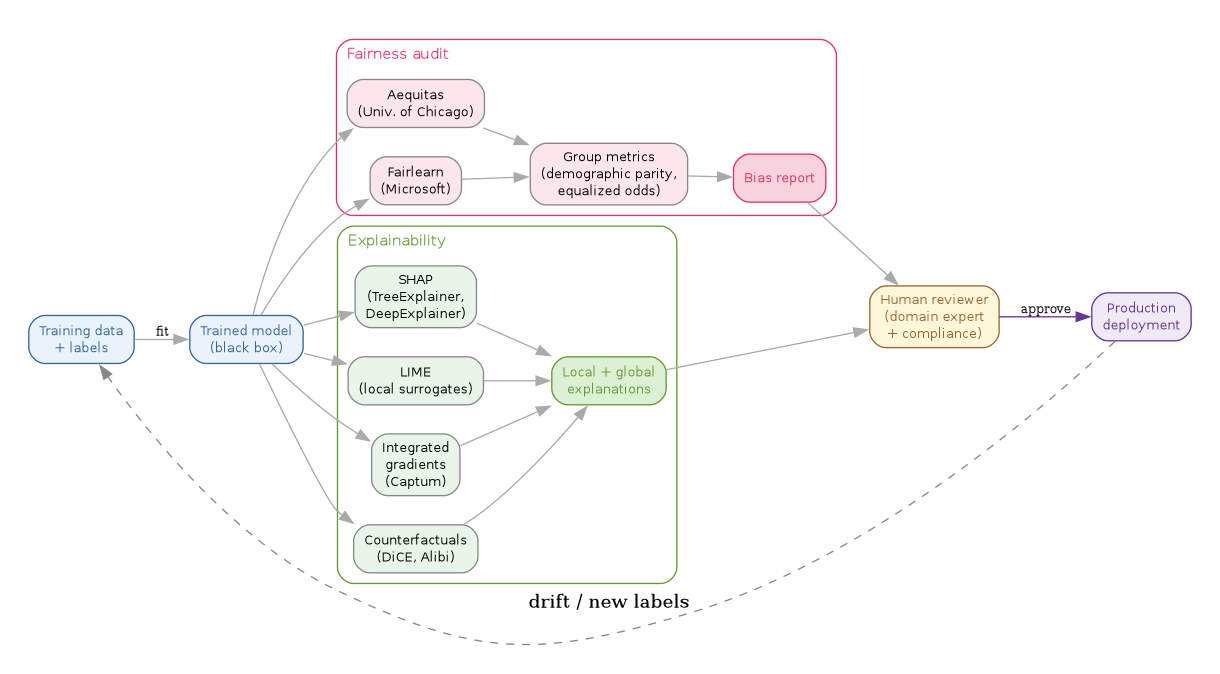
9. Related notes
- 2019 machine learning pipelines – the operational pipeline this oversight pass attaches to.
- Machine learning design patterns – has the surrounding pattern catalog (drift detection, retraining triggers).
- Fine-tuning ML models – interpretability shifts considerably when "the model" is an LLM rather than a tabular classifier.
- AWS DeepLens – companion 2019 note on the edge-deployment side of the same workflow.
10. Postscript (2026)
The interpretability stack consolidated faster than the original note expected. SHAP became the default tabular-model explainer (Lundberg's TreeExplainer / DeepExplainer / KernelExplainer covering most cases) and PyTorch shipped Captum in 2019, which absorbed integrated gradients, LayerWise Relevance, and most attribution-method research into a single library. Fairness consolidated into two toolkits: Fairlearn (originated at Microsoft Research, now community-maintained) and the University of Chicago's Aequitas; both ship group fairness metrics, mitigation algorithms, and audit reports out of the box. The harder regulatory frame arrived: the EU AI Act entered force on 1 August 2024 and introduced impact assessments and conformity requirements for high-risk systems (the categorisation that covers most fintech credit and insurance use cases). The frontier moved to LLMs: attribution methods that work for tabular and CNN models do not trivially extend to autoregressive text generation, and Anthropic's 2024 sparse-autoencoder and dictionary-learning research is the first practical mechanistic-interpretability toolkit to scale to a frontier model – see Scaling Monosemanticity (May 2024). The 2019 note's framing of "trust the prediction" vs "trust the model" still holds; the 2026 question is "trust which feature in the model".