Qwen3.6 and the KV Cache Constraint: Local-First Long-Context
Hybrid attention + TurboQuant, April 2026
Table of Contents
- 1. Overview
- 2. The contract: what local-first promises and what KV breaks
- 3. Refinement 1: hybrid attention reduces KV-bearing layers
- 4. Refinement 2: TurboQuant compresses the KV cache that remains
- 5. Backend contracts
- 6. The 27B-vs-35B-A3B choice
- 7. Falsification conditions
- 8. Provenance
- 9. Related

1. Overview
The binding constraint on local-first long-context inference is not
weights. It is the KV cache. Weights quantize cleanly to 4 bits and
stop scaling with sequence length. KV grows linearly in context and
quadratically in attention heads, and at 256K tokens it dominates the
memory budget on any consumer machine. Qwen3.6 (April 2026) and the
TurboQuant work in llama.cpp (November 2025 – April 2026) attack
this constraint from orthogonal directions: architectural and
numerical.
2. The contract: what local-first promises and what KV breaks
Local-first inference assumes (i) weights fit in unified memory or VRAM at some quant, (ii) context fits alongside weights, (iii) decode runs at read-out speed bounded by memory bandwidth. Invariant (i) is satisfied at Q4 for any model up to ~35B on 24–32GB hardware. Invariant (iii) is a property of the chip. Invariant (ii) is where local-first has been failing.
A dense 27B at fp16 KV consumes roughly 64 KB per token; at 200K tokens that is ~13GB of KV cache alone, on top of weights. The constraint binds before the user finishes their first agentic task.
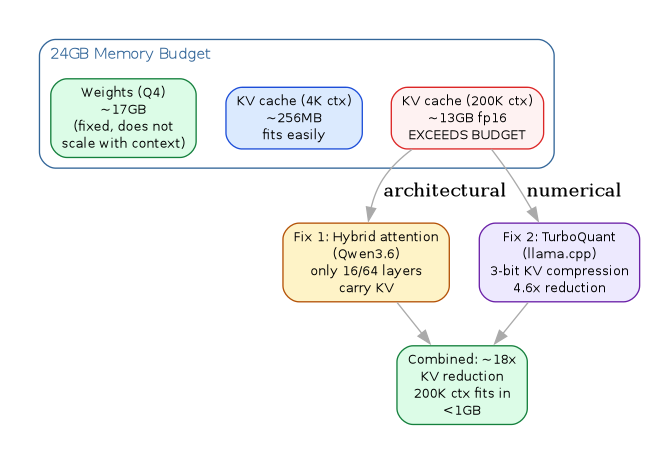
3. Refinement 1: hybrid attention reduces KV-bearing layers
Qwen3.6's architecture (both 27B dense and 35B-A3B MoE) interleaves
Gated DeltaNet (linear attention, O(n) state) with Gated Attention
(quadratic, KV-bearing) at a 3:1 ratio. The 64-layer network is 16
repeated blocks of (3 * DeltaNet -> 1 * GatedAttn). Only 16 of 64
layers carry a KV cache.

DeltaNet uses a delta-rule recurrence with rank-1 outer-product state updates, which gives associative-memory writes without a KV cache. Community measurement on Qwen3.5-35B-A3B (same hybrid stack) reported ~800 MB additional VRAM going from ctx=4096 to ctx=65536. The 256K native window on a 24GB card stops being a brag and becomes routine.
Provenance: model card and community reverse-engineering of the config. The Qwen team has not yet published a full Qwen3.6 technical report; the 35B-A3B and 27B model cards are the canonical source.
4. Refinement 2: TurboQuant compresses the KV cache that remains
Orthogonal to architecture, llama.cpp PR #20969 (TurboQuant) lands
3-bit KV cache compression via Randomized Hadamard Transform plus
Lloyd-Max scalar quantization. Block layout: 32 values -> 14 bytes
(2B fp16 scale + 12B packed 3-bit indices) = 3.5 bpw. KV per token
on hybrid Qwen3.5/3.6 drops from ~64 KB to ~14 KB, a 4.6x
compression.
Empirical refutation of the obvious "this destroys quality" prior: output identical to fp16 baseline on the 35B model at temperature 0. NIAH 6/6 exact retrieval. Quality degrades on 0.6B models, as predicted. The composition of hybrid-3:1 architecture and 3-bit KV quantization is multiplicative, not additive: 64 -> 16 KV layers, then ~4.6x compression on each, gives ~18x total reduction over a dense fp16 baseline.
5. Backend contracts
Three runtimes, three different invariants:
| Backend | Format | Strength | Constraint |
|---|---|---|---|
llama.cpp |
GGUF | Long-context after Turbo | Slower tok/s on small models vs MLX |
vLLM |
NVFP4 | Throughput, cont. batching | maxModelLen is hard, OOMs on graph |
MLX |
MLX | 20-87% faster <14B on M4 | Advantage collapses at 27B+ |
- llama.cpp owns the long-context envelope after TurboQuant. Reported configuration that served a 43K-token request on 2x 16GB consumer GPUs (Qwen3.6-27B NVFP4) where vLLM rejected the request before inference.
- vLLM wins on throughput at small context.
maxModelLenis a hard contract, not a hint, and it OOMs on graph capture before it ever sees a request that exceeds it. - MLX on Apple Silicon, unified memory. 20–87% faster than
llama.cppfor models <14B. Advantage collapses at 27B+ where memory bandwidth saturates and both backends hit the same ceiling. Full-prefill-before-first-token is the relevant aporia for interactive use.
Concrete numbers: M4 Pro 64GB on Qwen3-Coder-30B reports LM Studio (MLX) at 102 tok/s vs Ollama (llama.cpp) at 70 tok/s, with llama.cpp owning lower TTFT (0.18s vs 0.29s) and faster prefill at >32K context.
6. The 27B-vs-35B-A3B choice
Same family, two refinements of the same training run, opposite tradeoffs:
| Dimension | 27B dense | 35B-A3B MoE |
|---|---|---|
| Size at Q4 | ~17GB | ~22GB |
| Active params | 27B every token | 3B via router |
| Decode throughput | 1x | ~3x |
| SWE-bench Verified | 77.2 | 73.4 |
| Quantization | Predictable | Routing-sensitive |
| Target hardware | 24GB VRAM | 32–48GB unified (M4) |
The 27B beats the 397B-A17B Qwen3.5 flagship (76.2) on SWE-bench Verified. This is a narrow benchmark claim, not a general quality claim — see falsification conditions below.
For an M4 Mac Mini in the 32–48GB range the practical pick is 35B-A3B at Q4 or Q5 with thinking preservation enabled. For a 24GB-VRAM coding box, the 27B dense.
7. Falsification conditions
What would refute the thesis that hybrid attention plus TurboQuant solve the local-first long-context constraint:
- Sampling quality. KV-cache compression that is "identical at temp=0" but degrades measurably under sampling (top-p, top-k > 1). Untested in the public benchmarks so far.
- Agentic retrieval. Tool-use and agentic-coding tasks that require precise retrieval from positions >100K tokens deep. NIAH passes; agentic flows under TurboQuant are not yet characterized.
- MoE sensitivity. TurboQuant on 35B-A3B requires symmetric turbo4 per community testing, where dense 27B accepts asymmetric turbo3. The compression scheme is model-attention sensitive — "TurboQuant works" is not a general claim but a per-architecture conjecture.
- Benchmark narrowness. The 27B-beats-397B claim is SWE-bench Verified only. Multilingual, long-horizon-planning, and rare-language coding refutations should be expected.