Amazon DynamoDB: NoSQL Database Design
Table of Contents
1. Background
DynamoDB is a fully managed NoSQL database service from AWS that provides fast and predictable performance with seamless scalability.
1.1. Key Concepts
| Concept | Description |
|---|---|
| Partition Key | Primary key for data distribution |
| Sort Key | Optional secondary key for range queries |
| GSI | Global Secondary Index for alternate queries |
| LSI | Local Secondary Index (same partition) |
| RCU/WCU | Read/Write Capacity Units for throughput |
2. Creating a Table
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.create_table( TableName='Users', KeySchema=[ {'AttributeName': 'pk', 'KeyType': 'HASH'}, # Partition key {'AttributeName': 'sk', 'KeyType': 'RANGE'} # Sort key ], AttributeDefinitions=[ {'AttributeName': 'pk', 'AttributeType': 'S'}, {'AttributeName': 'sk', 'AttributeType': 'S'}, {'AttributeName': 'email', 'AttributeType': 'S'} ], GlobalSecondaryIndexes=[ { 'IndexName': 'email-index', 'KeySchema': [{'AttributeName': 'email', 'KeyType': 'HASH'}], 'Projection': {'ProjectionType': 'ALL'} } ], BillingMode='PAY_PER_REQUEST' )
3. Single-Table Design
Modern DynamoDB design uses a single table with composite keys:
# User record { 'pk': 'USER#12345', 'sk': 'PROFILE', 'name': 'Alice', 'email': 'alice@example.com' } # User's order { 'pk': 'USER#12345', 'sk': 'ORDER#2024-01-15#001', 'total': 99.99, 'status': 'shipped' } # Query all orders for a user response = table.query( KeyConditionExpression='pk = :pk AND begins_with(sk, :prefix)', ExpressionAttributeValues={ ':pk': 'USER#12345', ':prefix': 'ORDER#' } )
4. CRUD Operations
# Put item table.put_item(Item={'pk': 'USER#1', 'sk': 'PROFILE', 'name': 'Bob'}) # Get item response = table.get_item(Key={'pk': 'USER#1', 'sk': 'PROFILE'}) item = response.get('Item') # Update item table.update_item( Key={'pk': 'USER#1', 'sk': 'PROFILE'}, UpdateExpression='SET #n = :name', ExpressionAttributeNames={'#n': 'name'}, ExpressionAttributeValues={':name': 'Robert'} ) # Delete item table.delete_item(Key={'pk': 'USER#1', 'sk': 'PROFILE'})
5. Best Practices
- Design for access patterns, not entities
- Use single-table design when possible
- Avoid hot partitions with key design
- Use sparse indexes to reduce costs
- Enable point-in-time recovery for production
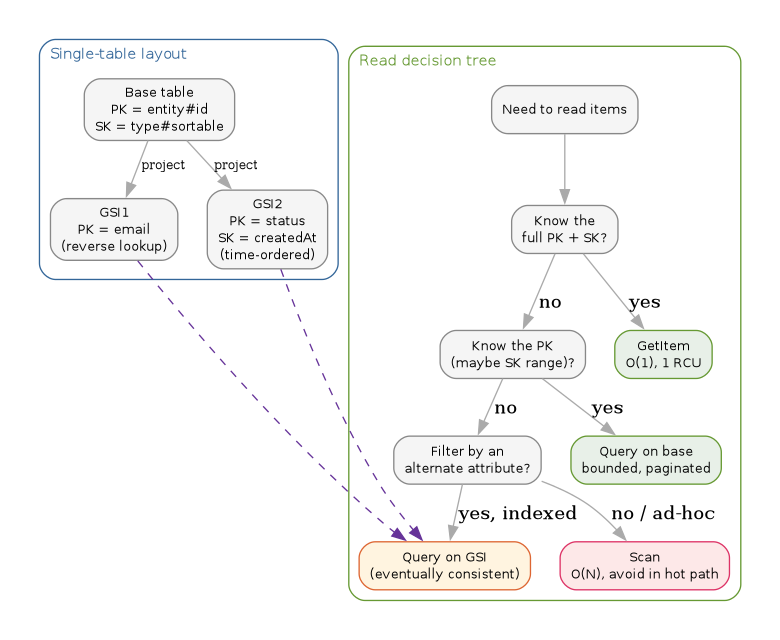
6. Access Patterns at a Glance
// DynamoDB -- single-table layout + scan/query/index decision tree digraph dynamodb_access { rankdir=TB; graph [bgcolor="white", fontname="Helvetica", fontsize=11, pad="0.3", nodesep="0.3", ranksep="0.35"]; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10, fillcolor="#dbeafe", color="#888"]; edge [color="#aaa"]; // Base table + GSIs subgraph cluster_table { label="Single-table layout"; labeljust="l"; color="#1d4ed8"; fontcolor="#1d4ed8"; style="rounded"; base [label="Base table\nPK = entity#id\nSK = type#sortable", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; gsi1 [label="GSI1\nPK = email\n(reverse lookup)", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; gsi2 [label="GSI2\nPK = status\nSK = createdAt\n(time-ordered)", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; base -> gsi1 [label="project", fontsize=9]; base -> gsi2 [label="project", fontsize=9]; } // Decision tree subgraph cluster_decide { label="Read decision tree"; labeljust="l"; color="#15803d"; fontcolor="#15803d"; style="rounded"; q0 [label="Need to read items", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; q1 [label="Know the\nfull PK + SK?", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; q2 [label="Know the PK\n(maybe SK range)?", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; q3 [label="Filter by an\nalternate attribute?", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; op_get [label="GetItem\nO(1), 1 RCU", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; op_query [label="Query on base\nbounded, paginated", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; op_gsi [label="Query on GSI\n(eventually consistent)", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; op_scan [label="Scan\nO(N), avoid in hot path", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; q0 -> q1; q1 -> op_get [label="yes"]; q1 -> q2 [label="no"]; q2 -> op_query [label="yes"]; q2 -> q3 [label="no"]; q3 -> op_gsi [label="yes, indexed"]; q3 -> op_scan [label="no / ad-hoc"]; } // Cross-cluster hint: GSIs satisfy the indexed branch gsi1 -> op_gsi [style=dashed, color="#6b21a8", constraint=false]; gsi2 -> op_gsi [style=dashed, color="#6b21a8", constraint=false]; }
7. Related notes
- Terraform – provision DynamoDB tables, GSIs, and IAM with the
aws_dynamodb_tableresource - Terraform Patterns – module patterns for stamping out per-environment table stacks
- Domain-Driven Design – aggregate boundaries map cleanly to single-table item collections
- GraphQL – DynamoDB resolvers (AppSync, Apollo) and the N+1 trap when fronting single-table designs
9. Postscript (2026)
Since this note was written, single-table design has firmly displaced the
"one table per entity" habit for new DynamoDB workloads, mostly thanks to
sustained advocacy from Rick Houlihan and the worked examples in Alex
DeBrie's The DynamoDB Book. Streams + Lambda has become the default fan-out
pattern: change-data-capture into OpenSearch, S3, or downstream microservices
is now a checkbox rather than a project. AWS shipped a first-party desktop
modeling tool, NoSQL Workbench for DynamoDB, which makes facet-based
single-table modeling tractable for teams that previously bounced off the
abstraction. For local dev and CI, DynamoDB Local (Docker or JAR) is the
standard – most teams stand it up in docker-compose alongside LocalStack
rather than hitting a real AWS account in tests. The 2022 launch of
on-demand mode with per-second billing also quietly killed most of the
"capacity planning" advice from earlier write-ups; provisioned mode is now
the exception, not the default.