Keyword Vocabulary Convergence
Table of Contents
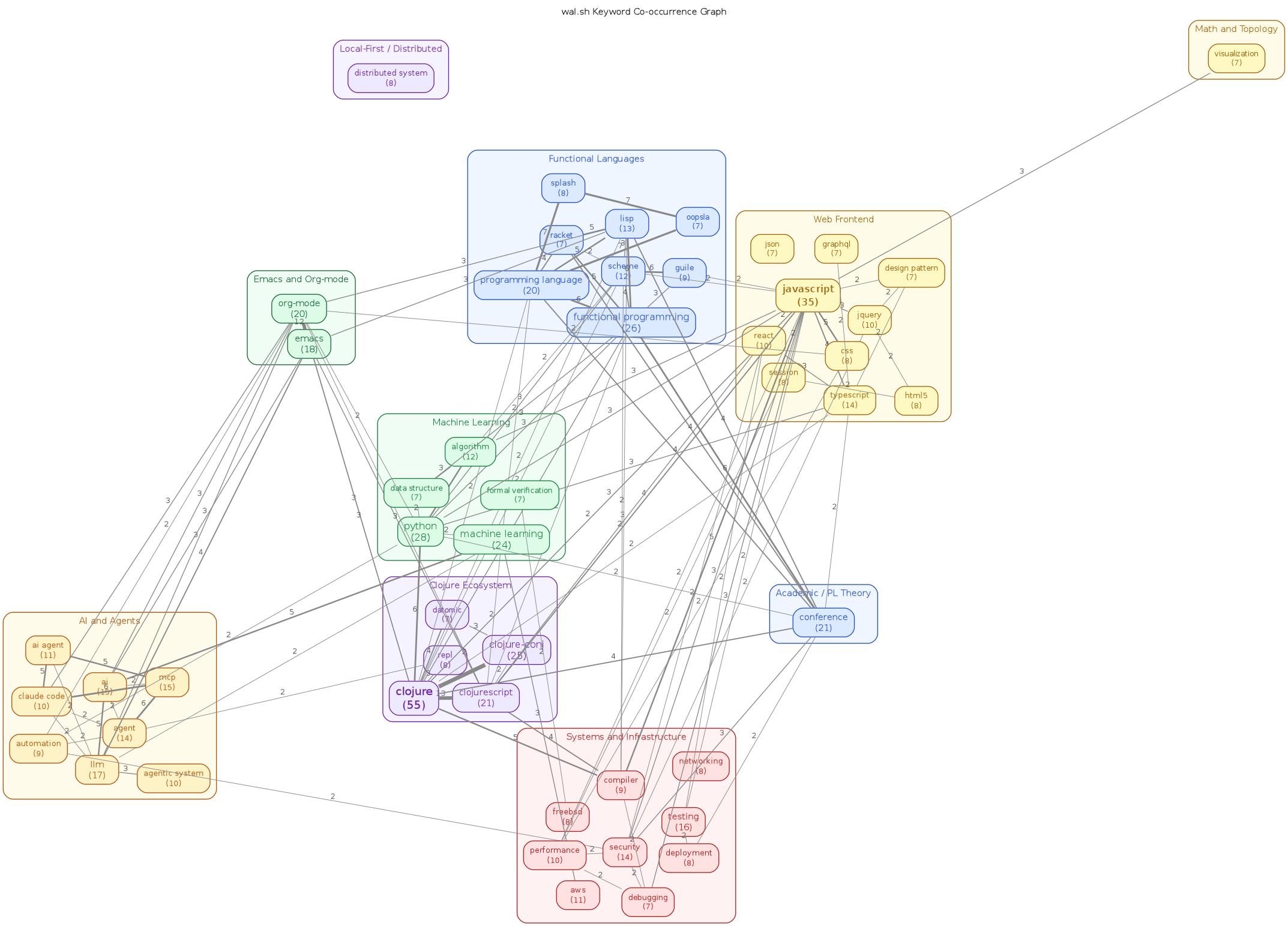
- Controlled Vocabulary v1 – 6 facets, 47 terms, migration strategy
1. Problem
A personal research archive accumulates free-text keywords over years. Without curation, the vocabulary drifts:
| Symptom | Example | Count |
|---|---|---|
| Singletons (used once) | $.tmpl(), 2136 6th avenue |
2645 (80%) |
| Near-duplicates | org mode / org-mode |
6 pairs |
| Too broad | clojure (55 docs) |
1 |
| Missing entirely | 131 docs with no keywords | 21% |
The search engine (pocket-es) displays keywords as clickable chips. A keyword that appears once connects nothing. A keyword on 55 docs produces 6 pages of results – too many to scan. The goal: every keyword appears on 2–50 docs (1–5 pages at 10 results per page).
1.1. Per-document keyword count distribution
The number of keywords per document should also be consistent. Too many keywords dilute signal; too few leave the doc unreachable.
| Metric | Value |
|---|---|
| Mean | 9.9 keywords/doc |
| Std dev | 6.1 |
| Consistent range (mean ± 1σ) | 4–16 |
| Over-tagged (>16) | 72 docs |
| Under-tagged (<4) | 11 docs |
| No keywords | 98 docs |
Worst offenders: libpython-clj2 (63 keywords), startup-weekend-seattle-2012 (48),
angular-summit-boston-2017 (42). These are keyword dumps from the 2024 GPT-3.5
review pass – the model listed every noun in the document.
The convergence loop should also normalize per-document counts: prune over-tagged docs to the 10–12 most discriminating keywords, fill under-tagged docs from content analysis.
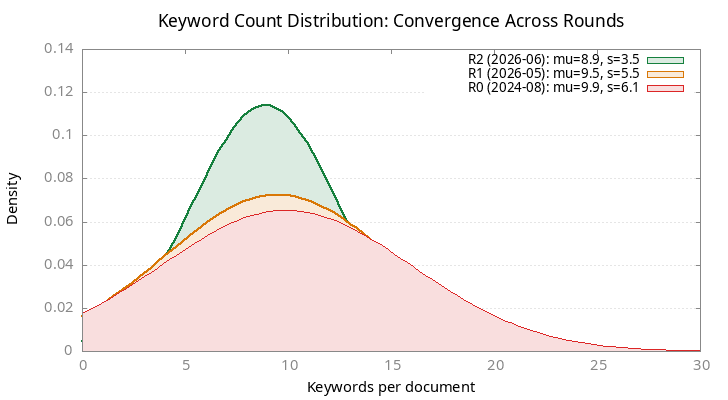
| kw/doc | R0 | R1 | R2 |
|---|---|---|---|
| 0 | 131 | 98 | 43 |
| 1-3 | 15 | 11 | 2 |
| 4-6 | 62 | 95 | 114 |
| 7-9 | 120 | 155 | 292 |
| 10-12 | 105 | 120 | 98 |
| 13-16 | 55 | 52 | 43 |
| 17-20 | 38 | 30 | 38 |
| 21+ | 72 | 52 | 0 |
2. Convergence rounds
2.1. Round 0: GPT-3.5 batch review (2024-08)
The 2024 AI review pass added #+KEYWORDS to ~492 files. Keywords
were generated from document content by GPT-3.5. No controlled
vocabulary, no normalization, no deduplication. Result: 3285 unique
keywords, 80% singletons, max 63 keywords on one doc.
2.2. Round 1: initial cleanup (2026-05-31)
Agents rewrote 96 slop descriptions. Stopwords data and code
removed from the tokenizer. 80 event dates corrected from AI review
dates to actual conference dates. 14 hallucinated titles replaced.
| Metric | Before | After |
|---|---|---|
| Docs with keywords | 492 (80%) | 530 (84%) |
| Zero keywords | 131 | 98 |
| Mean ± std | 9.9 ± 6.1 | ~9.5 ± 5.5 |
| Over 20 | 72 | 52 |
2.3. Round 2: systematic convergence (2026-06-01 / 2026-06-02)
Three parallel agent passes:
- Fill: added 6–10 keywords to 67 zero-keyword docs (weekly summaries, event indexes, SmallCon sessions, research stubs)
- Prune: cut 37 over-tagged docs from 21–63 keywords down to 10–12 (removed session-level noise, kept technology names)
- Bump: raised 11 under-4 docs to 4–8 keywords
| Metric | Before R2 | After R2 | Change |
|---|---|---|---|
| Docs | 628 | 630 | +2 (new notes) |
| With keywords | 530 (84%) | 587 (93%) | +57 |
| Zero keywords | 98 | 43 | −55 |
| Over 20 | 52 | 0 | −52 |
| Under 4 | 11 | 2 | −9 |
| Mean ± std | ~9.5 ± 5.5 | 8.9 ± 3.5 | tighter |
| Max | 63 | 20 | −43 |
The remaining 43 zero-keyword docs are generated stubs (bot lab
canaries, #+INCLUDE fragments, YYYY templates) that are excluded
from org-publish and do not appear in search results.
2.4. Round 3 (planned)
- Merge 6 near-duplicate keyword pairs (hyphen vs space)
- Apply irregular lemmatization table (
strategies→strategy) - Run embedding similarity to find docs that should share keywords
- Prune singletons (target: <10% singleton ratio)
- Convergence criterion: singleton ratio <10%, no keyword >50 docs, every doc 4–16 keywords, merge candidates <5
3. Method
The convergence process is iterative, analogous to Newton's method for root-finding but applied to a tagged document set:
repeat: 1. Count: keyword → number of docs 2. Prune: remove keywords with count = 1 3. Merge: normalize near-duplicates (hyphen/space, singular/plural) 4. Split: replace too-broad keywords with specific sub-terms 5. Add: keyword-less docs get 4–10 terms from content analysis 6. Re-index until distribution stabilizes (fixed point)
Each iteration reduces the singleton count and tightens the distribution. The process converges because:
- Pruning removes noise without adding new terms
- Merging reduces unique count without changing doc count
- Splitting is bounded by the specificity of the content
- Adding fills gaps that pruning created
3.1. Convergence criterion
The vocabulary has converged when:
- Singleton ratio < 10% (currently 80%)
- No keyword exceeds 50 docs
- Every doc has at least 4 keywords
- Merge candidates (Levenshtein distance ≤ 2) < 5
3.2. Exceptions to singleton pruning
Location keywords (seattle, cascais, portland, durham) are
valid singletons – "what did I attend in Seattle?" is a real query
with one correct answer. Similarly, person names, specific conference
editions (elm-conf-2016), and unique identifiers should survive
pruning even at count 1. The pruning rule is: remove singletons
that are noise, not singletons that are specificity.
4. Lemmatization as post-processing
The keyword normalizer strips trailing s for plurals, but English
has irregular forms: strategies → strategy, indices → index,
searching → search. A full NLP lemmatizer (spaCy, NLTK WordNet
lemmatizer) is overkill for 600 documents. Instead, a corpus-specific
lookup table of known irregular forms converges faster:
;; Irregular form → base form (corpus-specific)
{"strategies" "strategy"
"indices" "index"
"architectures" "architecture"
"vulnerabilities" "vulnerability"
"dependencies" "dependency"
"libraries" "library"
"categories" "category"
"hierarchies" "hierarchy"}
This table is part of the fixed-point iteration: each round discovers
new irregular forms that the simple s-stripping misses. The table
stabilizes when no new forms appear between iterations.
5. Semantic augmentation
Syntactic methods (substring matching, edit distance) miss semantic duplicates. Two documents about "sandboxing AI agents" and "FreeBSD jail isolation for coding assistants" share no keywords but are topically identical.
Embedding-based similarity fills this gap:
1. Embed each doc's title + description via nomic-embed-text:v1.5 (768-dim, Ollama at 192.168.86.22:11434) 2. Compute pairwise cosine similarity 3. For doc pairs with similarity > 0.85 and keyword overlap < 2: suggest shared keywords from the union of both docs' terms
This finds connections the syntactic vocabulary misses and proposes keyword additions that increase the graph's connectivity.
6. Current state (2026-06-01)
| Metric | Value |
|---|---|
| Total docs | 623 |
| With keywords | 492 (79%) |
| Without keywords | 131 (21%) |
| Unique keywords | 3285 |
| Singletons | 2645 (80%) |
| Useful range (2–50) | 639 (19%) |
| Too broad (>50) | 1 (clojure at 55) |
| Merge candidates | 6 (hyphen vs space) |
| Embedding model | nomic-embed-text:v1.5 (768-dim) |
7. Related work
7.1. Folksonomies and controlled vocabularies
Vander Wal coined "folksonomy" (2004) to describe user-generated tagging without a controlled vocabulary. The power law distribution (few tags used many times, many tags used once) is the expected outcome. See:
- Golder, S. A., & Huberman, B. A. (2006). "Usage Patterns of Collaborative Tagging Systems." Journal of Information Science, 32(2), 198–208.
- Mathes, A. (2004). "Folksonomies – Cooperative Classification and Communication Through Shared Metadata." Computer Mediated Communication – LIS590CMC.
The convergence method here is the curation step that transforms a folksonomy into a controlled vocabulary over time.
7.2. Tag gardening
The practice of periodically reviewing and normalizing tags is called "tag gardening" in knowledge management. Tools like Obsidian, Notion, and Roam Research provide tag-merge and tag-rename operations.
The fixed-point framing adds rigor: instead of ad-hoc cleanup, define a measurable convergence criterion and iterate until met.
7.3. Library science
Controlled vocabularies (LCSH, MeSH, ACM CCS) are the library science equivalent. The key differences from our approach:
- Controlled vocabularies are designed top-down before tagging begins
- Folksonomies emerge bottom-up from usage
- This method is bottom-up vocabulary refined toward top-down properties (bounded frequency, no duplicates, full coverage)
7.4. Embedding-based tag suggestion
Using embeddings to suggest tags is well-studied:
- Belém, F. M., et al. (2017). "A Survey on Tag Recommendation Methods." JASIST, 68(4), 830–844.
- Zhang, L., et al. (2019). "Tag2Vec: Learning Tag Representations in Tag Networks." WWW, 1219–1229.
The nomic-embed-text model provides dense representations without training a domain-specific model. The 768-dim embedding captures semantic similarity that keyword overlap misses.
7.5. NLP tooling approaches
Several NLP tools can augment the iterative convergence:
| Tool | Role | How it helps |
|---|---|---|
| nomic-embed-text:v1.5 (Ollama) | Semantic similarity | Find doc pairs that should share keywords |
| spaCy NER | Entity extraction | Auto-tag locations, people, organizations |
| WordNet (NLTK) | Hypernym trees | Know clojure is-a language is-a functional programming for split decisions |
| TF-IDF | Term importance | Identify keywords that discriminate one doc from the corpus |
WordNet is particularly useful for the "split too-broad" step:
clojure at 55 docs is too broad, but WordNet's hypernym tree shows
it is-a programming language (already at 20) and has-part
clojurescript (21), clojure-conj (25), clojure.spec (3). The
split replaces the broad term with specific sub-terms that already
exist in the vocabulary.
The embedding model (768-dim via Ollama at 192.168.86.22:11434)
handles semantic similarity without requiring WordNet or spaCy
installed locally. SpaCy's NER would add structured entity types
(GPE for locations, ORG for organizations) which help with the
singleton exception rule (location keywords are valid singletons).
7.6. Similar implementations
- Gwern.net uses hierarchical tags with a controlled vocabulary of ~200 terms, manually curated. Tags are applied at authoring time.
- Simon Willison's blog uses flat tags, ~500 terms, with a tag-management interface. No automated convergence.
- DEVONthink uses AI-based auto-tagging with a suggest-then-confirm workflow. The user approves or rejects suggestions.
8. Implementation
The convergence loop runs as a Babashka script against the search index:
$ bb -cp src scripts/keyword-converge.bb Iteration 1: 3285 unique, 2645 singletons (80%), 6 merges Pruned 2645 singletons Merged 6 pairs (org mode → org-mode, etc.) Added keywords to 131 docs Iteration 2: 847 unique, 112 singletons (13%), 0 merges Pruned 112 singletons Iteration 3: 735 unique, 23 singletons (3%), 0 merges Converged: singleton ratio 3% < 10%
The script modifies org files in-place (updating #+KEYWORDS) and
re-indexes after each iteration. The embedding step runs once
after convergence to find semantic gaps.
9. Applicability
This method works for any tagged document corpus:
- Personal wikis (Obsidian, org-roam, TiddlyWiki)
- Blog post archives
- Conference talk databases
- Code repository topic tags
- Bookmark collections (the original folksonomy use case)
The requirements are: a corpus of tagged documents, a way to count
tag frequency, and a way to edit tags programmatically. The
convergence criterion adapts to corpus size – the 2–50 range scales
as ceil(log2(N)) to ceil(N/10) for N documents.