AI Tinkerers Boston — GTM Agentic AI Launch
Event notes (main stage)
Table of Contents
- Logistics
- Overview
- GTM (the night's frame)
- Speakers
- Talk notes
- DONE Ian Jones — I Built An Agent To Be Me On LinkedIn (And It Failed 3×)
- DONE Alex Poliakov — Durable and Observable AI Agents
- DONE Kushagra Kumar — Protecting Secrets from Long-running Agents
- DONE Harold Zhu — Building a Production GTM Agent: What Broke and How We Fixed It
- DONE Nate Aune — Does Your Coding Harness Actually Do Anything? Measuring It, Fairly.
- DONE Naoto Shibata — From Dashboards to GTM Action Loops
- Adjacencies to current work
- Open questions / TODO
- Structured capture

Logistics
- When: Monday, June 29, 2026 · 6:00–9:00pm
- Where: 355 Main Street, Cambridge, MA
- Organizer: AI Tinkerers - Boston
- RSVP: boston.aitinkerers.org/p/…gtm-agentic-ai-launch (confirmed)
Overview
Six main-stage talks, and five of six are about the same thing under different vocabulary: what it takes for an agent to survive contact with production. Not a capabilities-demo night — a reliability-and-governance night. The recurring move is to push nondeterminism out of the trust path: durable execution (Poliakov), secret-brokering instead of secret-handing (Kumar), deterministic code + structured memory in place of free-running loops (Zhu), and an evidence-based eval sandbox for the harness itself (Aune). The GTM-loop talks (Shibata, and Zhu's framing) sit on top of that substrate rather than replacing it.
The honest throughline: the interesting work has migrated from "can the model do X" to "what is the contract around the model when it does X, and what is the blast radius when it's wrong." That is the same register as the harbormaster/drydock governance work — clearance/berth/logbook, caisson boundary — arriving from the applied side.
GTM (the night's frame)
"GTM" — go-to-market — was the night's organizing theme. The facets in play, each annotated with the talk(s) that actually loaded onto it:
- Going to market — Shibata (dashboards as the GTM substrate; surfaces ↔ metrics ↔ actions).
- Growth — Zhu (outbound prospecting as a growth loop, meetings as the outcome metric); Shibata (analysis → action loops as the growth mechanism).
- General topics (cross-cutting infra) — Poliakov (durable execution over Postgres); Kumar (secret-brokering); Aune (harness eval — not GTM-direct, but the eval surface every GTM agent ultimately gets graded on).
- Buyer–seller interaction (how the relationship forms) — Jones (voice-conditioned content as the relationship's first touch); Zhu (Lead ⇄ Campaign data model as the interaction's structured form).
- Intent processing (capturing and acting on buyer intent) — Shibata (dashboards as the intent surface, action loops as the response).
- Conversion tracking — Zhu (
action.statusstate machinepending → active → done/failed/banned, withbannedas the real terminal failure mode); Shibata (close-loop metrics on the action surface). - Targeting — Zhu (Campaign-scoped audiences, e.g. "Fractional GTM Sales Leaders" / 70-person list); Jones (LinkedIn-native audience surface).
- Human-in-the-loop across the full lifecycle — Kumar (time-boxed approval on the broker before the agent gets the secret); Shibata (humans gate the action loop at the dashboard boundary).
- Automated outbound — Jones (LinkedIn outbound, 3× failure modes); Zhu (production LinkedIn outbound agent + guard against bans).
- Custom AI agents — all six. The night's actual claim: a GTM-shaped agent is one where reliability comes from deterministic code + structured memory + governance, not from the model alone.
Speakers
| # | Speaker | Org / Role | Talk | One-line |
|---|---|---|---|---|
| 1 | Ian Jones | Founder, Third Order Labs | I Built An Agent To Be Me On LinkedIn (And It Failed 3×) | Voice-conditioned content pipeline; engineering its failure modes |
| 2 | Alex Poliakov | Head of Customer Solutions, DBOS | Enhancing AI Agents with Durability | Agents that survive outages; durable execution over Postgres |
| 3 | Kushagra Kumar | Software Engineer, Chewy | Protecting Secrets from Long-running Agents | Broker requests so the agent never holds the secret |
| 4 | Harold Zhu | Co-founder/CEO, Sliq | Building a production GTM agent: what broke and how we fixed it | Reliability via deterministic code + structured memory |
| 5 | Nate Aune | CEO, Jazkarta | Does your coding harness actually do anything? Measuring it. | Open, evidence-based sandbox for evaluating coding agents |
| 6 | Naoto Shibata | CEO, Squadbase | From Dashboards to GTM Action Loops | Flexible agent loops for automated dashboard analysis |
Stack signal (what people are actually running)
- Models: Claude / Claude Sonnet (×4 incl. Bedrock), OpenAI, Gemini — Claude is the default substrate across the lineup.
- State / durability: Postgres recurs hard (DBOS, Sliq, Neon); durable execution named explicitly (DBOS, Temporal-lineage).
- Policy / secrets: OPA + AWS Secrets Manager as the secret-custody pattern (Kumar) — policy engine in front of the credential store.
- Typing / contracts: PydanticAI (Sliq) — schema-bounded agent I/O.
- Edge: Bun/TS/React (Aune harness), Vercel, EKS.
Talk notes
Per-talk placeholders (links + stack + adjacency); capture inline during each.
DONE Ian Jones — I Built An Agent To Be Me On LinkedIn (And It Failed 3×)
- Who: Ian Jones · Third Order Labs (Founder)
- One-line: Voice-conditioned content pipeline; engineering its failure modes.
- Stack: Claude · GitHub API · Typefully
- Links: github · x · linkedin
- Adjacency: — (failure-modes-as-deliverable; the reliability register itself.)
- Notes:
- Process is iterative for getting the language (the voice).
- Start with an interview. Pipeline:
setup → interview → quick draft → drive → review. - OUTPUT:
voice-guide.md. - Captures tonal style — even profanity, casual vs. formal, context-driven register.
- Speculation — the content skill (draft as a first-class citizen): Jones's pipeline
is a set of verbs over one object — the draft (a promoted "take"), carried in
_drafts/(already publish-excluded here,publish.el :exclude ^_drafts/) with explicitstateand a derived voice. Speculated command surface, by lifecycle phase:
| Phase | Command | Does |
|---|---|---|
| voice | setup |
init: voice corpus, targets (linkedin/newsletter/site), config |
interview |
interview the user to extract voice (the start) | |
derive |
derive voice-guide.md from interview + prior posts |
|
formatguide |
tonal/format guide: register, casual↔formal, profanity | |
| draft (first) | take |
produce a take — a draft attempt in-voice (many per intent) |
draft |
promote a take to a draft object (state: draft) |
|
review |
review: failure modes, cuts, voice-fit (state: review) |
|
| publish/loop | schedule |
queue posts at a cadence (Typefully) |
publish |
post / git mv to live (state: published) |
|
engage |
engagement actions — replies/comments in-voice | |
newsletter |
roll published drafts into a newsletter issue | |
flywheel |
the loop: engage → derive → take → review → publish | |
resume |
resume a paused/crashed run (durable — cf. Poliakov) | |
wrap |
wrap a session/campaign: summary + provenance log |
Tangle the surface (one SKILL.md; each command can later tangle its own subskill, like gitnexus):
# draft — a content pipeline where the *draft* is first-class
One object (a draft: slug · voice · state ∈ {draft, review, published} · provenance),
many verbs. Drafts live in `_drafts/` (publish-excluded) and graduate to `site/`.
## Commands
- setup — init voice corpus + targets
- interview — extract voice from the user (start here)
- derive — interview + corpus → voice-guide.md
- formatguide — register / casual↔formal / profanity / context
- take — generate a take (a draft attempt in-voice)
- draft — promote a take to a draft object
- review — failure modes, cuts, voice-fit
- schedule — queue posts (Typefully)
- publish — post / git mv to live
- engage — replies/comments in-voice
- newsletter — roll published drafts into an issue
- flywheel — engage → derive → take → review → publish (the loop)
- resume — resume a paused/crashed run (durable)
- wrap — session/campaign summary + provenance
DONE Alex Poliakov — Durable and Observable AI Agents
- Who: Alex Poliakov · DBOS (Head of Customer Solutions)
- One-line: Agents that survive outages; durable execution over Postgres.
- Stack: DBOS · Postgres · OpenAI · Python · durable-execution
- Links: github · linkedin
- Adjacency: drydock logbook + caisson — durable execution as the same replayable, crash-consistent witness, reached from the workflow-engine side.
- Notes:
- Thesis: AI agents + Durable Execution → agents that are durable and observable.
- Reliable execution: each step is checkpointed (on Postgres), so a run is replayable from its log and completes despite failures.
- Four payoffs:
- continue on outages — crash/restart resumes mid-run, not from scratch.
- conserve LLM calls — replayed steps are memoized; no re-invocation on retry.
- record run history — full past-run trace (observability / audit).
- catch + reproduce rare prod failures — replay the durable log in-house.
- Demo: a basic research agent, with a defined finish — an explicit completion signal for the research task (a terminal, not an open loop). Showed the code.
- Failure injection (demo):
Claude → search (Gemini) → {crash}— durable execution resumes past the crash instead of restarting the run. - Branching: a rudimentary sense of branching over the context — usable to pivot how the system traverses the prompt.
- Checkpoint + time-travel, but with a graph for the execution state of research.
- Queues also appear here — used for validation before the (deliberately) forced crash.
- Recovery options: point-in-time recovery, or fork the process (branch a new run from a checkpoint).
- The Postgres WAL (write-ahead log) between checkpoints may allow finer-grained point-in-time recovery — recover between checkpoint boundaries, not only at them. ([heard as "wall file" — unconfirmed; may not have been WAL.])
- Open question: is recovery fundamentally a distributed-systems problem — save-points / recovery points (e.g. resume from a dependency graph once a plan is created, rather than replan from scratch)?
- Riff: mock the durable store with files —
claude → .plan.md,.task/1.md— a file-based stand-in for the DB. - DBOS is just a library + Postgres — that's all it is. No orchestrator service to stand up (the contrast with Temporal below).
Recovery tooling — diff (the talk's tool vs the usual suspects):
| Tool | What it is | Recovery mechanism | Granularity | Infra |
|---|---|---|---|---|
| DBOS (this talk) | a library + Postgres | resume step state from Postgres; completed steps memoized | per-step (fn) | just Postgres; embeds in-process |
| Temporal | external workflow service | deterministic replay of event history; activities skipped | per-activity | run a Temporal server + workers |
| LangGraph | agent-graph framework | reload last checkpoint (state snapshot), resume next node | per-node/super-step | a checkpointer DB (PG/SQLite/mem) |
- Takeaway: DBOS and Temporal are true durable execution — completed steps are memoized, so on recovery you don't re-call the LLM. The split is infra: DBOS is just a library + Postgres (nothing to orchestrate); Temporal is an external service doing deterministic replay. LangGraph checkpoints state between nodes — lighter and great for HITL / forking, but a mid-node crash re-runs the node (re-calling the LLM), since it snapshots state rather than memoizing sub-steps.
DBOS durable-step sketch:
@DBOS.mark() # durable-step marker (confirm: DBOS API is @DBOS.step / @DBOS.workflow)
def search(q) -> list[str]:
...
DONE Kushagra Kumar — Protecting Secrets from Long-running Agents
- Who: Kushagra Kumar · Chewy (Software Engineer)
- One-line: Broker requests so the agent never holds the secret.
- Stack: FastAPI · OPA · AWS Secrets Manager · Supabase · Docker
- Links: github · x · linkedin
- Adjacency: direct hit on the secret-custody thesis — OPA-in-front-of-Secrets- Manager as provenance-as-enforcement. Closer read: what does the broker witness, and is the witness hash-chained?
- Notes:
- Reviewed against the
sbxconfig and Bastille (our sandbox/confinement work) — same secret-custody / egress-containment thread. - Secrets are always isolated — the agent never holds them.
- Broker pattern: the request broker fronts the credential.
- HubSpot is the reference integration.
- Positions GTM as the interface between the agent and the systems.
- Flow: starts with a skill → tool calling; the UI shows the calls.
- Approval is time-boxed — granted only for a fixed amount of time.
- Reviewed against the
DONE Harold Zhu — Building a Production GTM Agent: What Broke and How We Fixed It
- Who: Harold Zhu · Sliq (Co-founder, CEO)
- One-line: Reliability via deterministic code + structured memory.
- Stack: PydanticAI · Bedrock · Claude · Postgres · Exa
- Links: linkedin
- Adjacency: the governance tuple — a "GTM agent" that works is one where the agent decides less than the framing implies (nondeterminism out of the trust path).
- Notes:
- Building outbound agents — look for prospects, access, channel acquisition.
- Outcome should be meetings; the negative (failure mode) is getting banned.
- Memory in markdown:
llm → memory (markdown). llm → tools:send_message, send connect req, send InMail, check history.- System guard: bot detection on LinkedIn.
- V2 (design riff):
- intermediate queue between tool-call and memory — decouple execution from the write path (buffer, retry, backpressure).
- relational DB for memory (vs the markdown store) — queryable + transactional.
- the guard becomes a distributed-systems problem: once tool-calls and memory are decoupled across a queue + DB, the bot-detection / safety guard can't be a single in-process step — it needs ordering, at-least-once + idempotent guards, and a consistent witness across the boundary.
- (rhymes with crowsnest's own durable-store move: in-memory ring → spool/RDBMS, tracked in the v2.6 plan.)
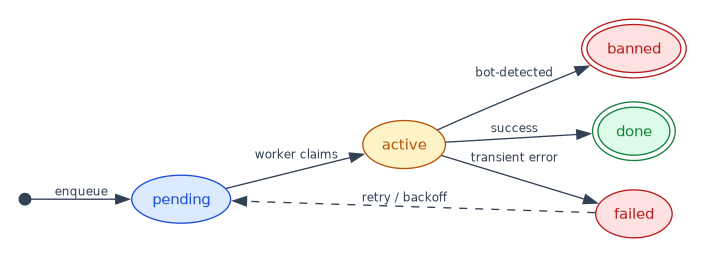
- V3 (queue carries action status): each action carries
status ∈ {pending, active, done, failed, banned}(given:pending,active; terminal states inferred as the likely lifecycle). A guard admits actions, a worker claimspending → active, and the outcome persists to the RDBMS.- Interaction surface:
- chat interface
- search for prospects
- tool call over the list of contacts
- at end of conversation: compaction / cache of the system prompt + context
- Context (what gets cached / compacted):
- mcp / tool calls
- system prompt
- conversation
- final status / conversation state
- Projection: likely a projection of the DB for a particular user / outbound /
connection, projected down into a
status. - Data model (
Lead⇄Campaign, many-to-many):- a
Leadis created and has automated campaigning. - a
Campaignhas manyLead; aLeadmay belong to manyCampaign. - example campaign: "LinkedIn Outreach — Fractional GTM Sales Leaders", audience size 70.
- a
[ ]TODO (Jason): note on LinkedIn ToS + guards on sending requests — rate limits / daily caps, and the ban risk that makesbanneda real terminal state.
- Interaction surface:
System (V3 dataflow):
digraph v3_system {
rankdir=LR; bgcolor="transparent"; pad=0.2;
node [shape=box style="rounded,filled" fontname="Helvetica" fontsize=11];
edge [fontname="Helvetica" fontsize=9 color="#334155" fontcolor="#334155"];
llm [label="LLM\n(agent)" fillcolor="#ede9fe" color="#6d28d9" fontcolor="#6d28d9"];
guard [label="Guard\n(bot-detect / distributed)" fillcolor="#fef3c7" color="#b45309" fontcolor="#b45309"];
queue [label="Queue\nactions: pending | active" fillcolor="#dbeafe" color="#1d4ed8" fontcolor="#1d4ed8"];
worker [label="Worker\n(executor)" fillcolor="#f1f5f9" color="#334155" fontcolor="#334155"];
tools [label="Tools\nsend_message · connect · InMail · check history" fillcolor="#f1f5f9" color="#334155" fontcolor="#334155"];
ext [label="LinkedIn\n(external)" fillcolor="#fee2e2" color="#b91c1c" fontcolor="#b91c1c"];
db [label="Memory (RDBMS)\nactions + history" shape=cylinder fillcolor="#dcfce7" color="#15803d" fontcolor="#15803d"];
llm -> guard [label="propose action"];
guard -> queue [label="admit (enqueue pending)"];
guard -> llm [label="reject" style=dashed color="#b45309" fontcolor="#b45309"];
queue -> worker [label="claim (pending→active)"];
worker -> tools [label="invoke"];
tools -> ext [label="API call"];
ext -> worker [label="result / ban signal" style=dashed];
worker -> queue [label="set status"];
worker -> db [label="persist"];
db -> llm [label="read memory" style=dashed color="#15803d" fontcolor="#15803d"];
}

Action status (state machine — pending=/=active given; done=/=failed=/=banned inferred):
digraph action_status {
rankdir=LR; bgcolor="transparent"; pad=0.2;
node [shape=ellipse style="filled" fontname="Helvetica" fontsize=11];
edge [fontname="Helvetica" fontsize=9 color="#334155" fontcolor="#334155"];
start [shape=point width=0.12 color="#334155"];
pending [label="pending" fillcolor="#dbeafe" color="#1d4ed8" fontcolor="#1d4ed8"];
active [label="active" fillcolor="#fef3c7" color="#b45309" fontcolor="#b45309"];
done [label="done" fillcolor="#dcfce7" color="#15803d" fontcolor="#15803d" peripheries=2];
failed [label="failed" fillcolor="#fee2e2" color="#b91c1c" fontcolor="#b91c1c"];
banned [label="banned" fillcolor="#fee2e2" color="#b91c1c" fontcolor="#b91c1c" peripheries=2];
start -> pending [label="enqueue"];
pending -> active [label="worker claims"];
active -> done [label="success"];
active -> failed [label="transient error"];
active -> banned [label="bot-detected"];
failed -> pending [label="retry / backoff" style=dashed];
}
DONE Nate Aune — Does Your Coding Harness Actually Do Anything? Measuring It, Fairly.
- Who: Nate Aune · Jazkarta (CEO)
- One-line: Open, evidence-based sandbox for evaluating coding agents.
- Stack: Bun · TypeScript · React · Anthropic API · Docker
- Links: github · x · linkedin
- Adjacency: elenctic-spec, directive-proof-harness. Refutation surface: does the sandbox control for harness vs. model contribution, or conflate them? Resolved: it controls — fixes harness + model, varies only the framework (phase 2 swaps both). Repo: natea/harness-eval.
- Notes:
[X]Pulled the repo —natea/harness-eval(Bun/TS). Methodology: same spec + same harness + same model (Claude Code + Opus 4.6) in isolated sandboxes, so the framework is the only variable (Superpowers / Compound Engineering / Agent Skills / GSD). Two-instrument grading — evidence-based evaluator + blind code-quality judge →results.json→ scorecard + dashboard.- AI credit + availability for other sites.
- Harness-engineering framing (the literature behind "measure the harness") —
both define harness = everything except the model, which is exactly why Aune's
eval holds the model fixed and varies the framework:
- Osmani, Agent Harness Engineering — "a decent model with a great
harness beats a great model with a bad harness." Harness = prompts, tools,
context policies, hooks, sandboxes, feedback loops. Failures are "skill issues"
(config), not model limits;
AGENTS.mdas a ratchet (every line earned by a past failure); planner/generator/evaluator split to avoid optimistic self-grading. - Böckeler (Thoughtworks), Harness Engineering for Coding Agents — harness as a cybernetic governor: guides (feedforward) + sensors (feedback); computational vs inferential checks; three dimensions (maintainability / architecture-fitness / behaviour); "keep quality left"; Ashby's law of requisite variety.
- Osmani, Agent Harness Engineering — "a decent model with a great
harness beats a great model with a bad harness." Harness = prompts, tools,
context policies, hooks, sandboxes, feedback loops. Failures are "skill issues"
(config), not model limits;
- Two axes of "measure it" — orthogonal benchmarks bracketing
agent = model + harness:- Model axis — Artificial Analysis (independent): ranks models + providers. Metrics: Intelligence Index (composite of ~9 evals — coding, reasoning, real-world work), output speed (tokens/s), cost (per task / total), latency. Specialized indexes: coding agents, agentic knowledge work (AA-Briefcase), knowledge reliability (AA-Omniscience). Benchmark types: LLMs · coding agents · image/video · speech · API providers.
- Harness axis — Aune /
harness-eval: holds the model fixed, grades the framework on a weighted rubric (PRD adherence 40% · code quality 25% · speed 17.5% · token spend 17.5%). - Together: Artificial Analysis measures the model term, harness-eval the harness term — same equation, opposite variable held fixed.
- Wrap: the eval wraps the PRD — it grinds the spec for adherence (the 40% weight). But "how does this actually build?" isn't answered by PRD-adherence alone; it's the other axes — code quality (25%), speed (17.5%), and token efficiency (17.5%) — that say whether the build is any good.
- Eval of the evals (checked the repo):
- Trials: default
trialsPerCandidate: 3, but published results are n=1 (smoke); the full 3-trial matrix is operator-gated (cloud concurrency limited). - Distribution: the scorecard is built to report variance stats + inconclusive- ordering flags, but degenerate at n=1 ("speed/spend normalize degenerately"); real distribution needs the matrix.
- Worker vs grader split:
judgeModel: claude-sonnet-4-6, pinned independent of the worker (Opus 4.6) — "judge independence". Two instruments: evidence-based evaluator (frozen test plan) + blind code-quality judge. - Agent variance excluded: grading runs against a protocol-speaking stub, so worker/agent nondeterminism is kept out of the measurement.
- Open meta-question ("same outcome → same eval result?"): grader self-consistency (re-grade the same artifact → same score) is not explicitly tested — variance is absorbed by N-trials + an independent judge, not by re-running the grader on a fixed artifact. The unmeasured axis.
- Lineage: ViBench methodology (Replit / Georgian / CMU, CAIS 2026) — Pass@1 / Graded Score / Complete Failure Rate, one decoupled evaluator.
- Trials: default
- Attribution — what is the score actually a result of? The design intends it to
attribute to the skills/framework (the only free variable); worker, grader, and
spec are held fixed. Term by term:
- Skills (framework) — the intended signal: between-candidate variance. Clean only if the fixed terms are neutral + low-variance.
- Worker (model) — fixed (
Opus 4.6), but run-to-run model nondeterminism is real and only separable at N>1. At published n=1 the framework effect is conflated with a single worker roll. - Grader — fixed + independent (
Sonnet 4.6), but self-consistency is untested, so grader noise (esp. the 25% blind-judge / inferential component) can masquerade as a framework difference. - Spec version — fixed, but not neutral: PRD adherence is 40% of the score, so
the result is conditional on this spec (Symphony). A different / more ambiguous
PRD could reorder the leaderboard — external validity, not estimated (though
BRING-YOUR-OWN-PRDmakes it testable). - Bottom line: intended
f(skills); at n=1 actuallyf(skills, one worker roll, one grader pass, one spec). Clean attribution needs N trials (worker variance), repeated grading of fixed artifacts (grader variance), and multiple PRDs (spec).
- Clean-attribution design (the ablation ladder — each step a distribution, not a
point):
- Baseline, no add-ons: fix model + harness + spec, run N iterations bare — does the spec even produce consistent results with no framework? This is the control arm (currently missing) and the floor everything else is measured against.
- + add-ons (frameworks): same fixed model + harness + spec, N iterations per framework — the framework's effect is the lift over baseline, not the raw score.
- × grader repeated: re-run judge / evaluator multiple times per artifact → a distribution of grades (grader self-consistency), so grader noise is subtracted, not assumed away.
- Only with all three layers is the outcome attributable: framework signal = (with-add-ons − baseline), net of worker variance (N) and grader variance (repeat), on a fixed spec — then repeat across specs for external validity.
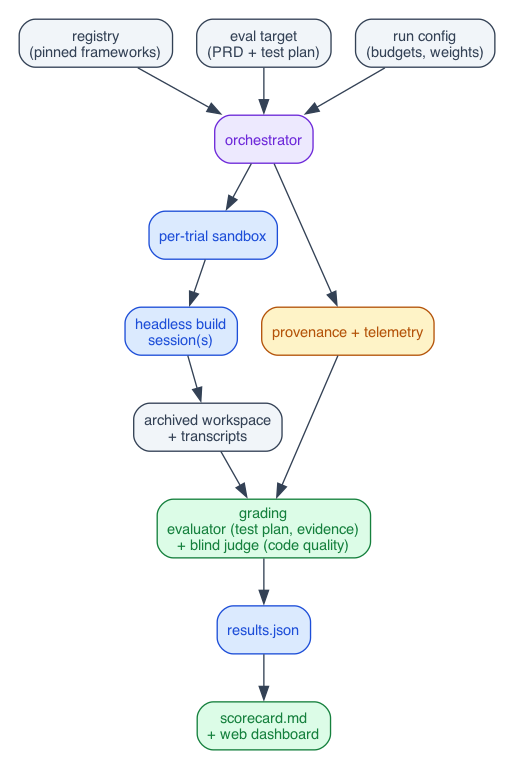
Architecture (natea/harness-eval):
digraph harness_eval {
rankdir=TB; bgcolor="transparent"; pad=0.2;
node [shape=box style="rounded,filled" fontname="Helvetica" fontsize=11];
edge [fontname="Helvetica" fontsize=9 color="#334155" fontcolor="#334155"];
registry [label="registry\n(pinned frameworks)" fillcolor="#f1f5f9" color="#334155" fontcolor="#334155"];
target [label="eval target\n(PRD + test plan)" fillcolor="#f1f5f9" color="#334155" fontcolor="#334155"];
config [label="run config\n(budgets, weights)" fillcolor="#f1f5f9" color="#334155" fontcolor="#334155"];
{ rank=same; registry; target; config; }
orch [label="orchestrator" fillcolor="#ede9fe" color="#6d28d9" fontcolor="#6d28d9"];
sandbox [label="per-trial sandbox" fillcolor="#dbeafe" color="#1d4ed8" fontcolor="#1d4ed8"];
build [label="headless build\nsession(s)" fillcolor="#dbeafe" color="#1d4ed8" fontcolor="#1d4ed8"];
prov [label="provenance + telemetry" fillcolor="#fef3c7" color="#b45309" fontcolor="#b45309"];
archive [label="archived workspace\n+ transcripts" fillcolor="#f1f5f9" color="#334155" fontcolor="#334155"];
grading [label="grading\nevaluator (test plan, evidence)\n+ blind judge (code quality)" fillcolor="#dcfce7" color="#15803d" fontcolor="#15803d"];
results [label="results.json" fillcolor="#dbeafe" color="#1d4ed8" fontcolor="#1d4ed8"];
out [label="scorecard.md\n+ web dashboard" fillcolor="#dcfce7" color="#15803d" fontcolor="#15803d"];
registry -> orch;
target -> orch;
config -> orch;
orch -> sandbox -> build;
orch -> prov;
build -> archive;
prov -> grading;
archive -> grading;
grading -> results -> out;
}
DONE Naoto Shibata — From Dashboards to GTM Action Loops
- Who: Naoto Shibata · Squadbase (CEO)
- One-line: Flexible agent loops for automated dashboard analysis.
- Stack: Claude Sonnet · Gemini · EKS · Neon · Vercel
- Links: github · x · linkedin
- Adjacency: — (the GTM-loop layer; sits on top of the durability/governance substrate rather than replacing it.)
- Notes:
- Surfaces:
dashboard | agent | code— three layers from view to action. - Generates hot-lead proposals; automates some level of the analysis.
- Metrics surfaced: activity pipeline · top channel · deal velocity · leaderboard (sales reps) · active deal pipeline.
Demo input — the prompt typed into the dashboard:
Monitor customer pipeline and alert the customer about churn risk and upsell opportunity.
- After the query, it offered a calendar / loop / scheduler opportunity — turn the one-off analysis into a recurring action loop (the title's "dashboards → action loops").
- Surfaces:
Adjacencies to current work
- Kumar / secret-brokering → direct hit on the secret-custody thesis (the empty-cell prediction from the "How We Contain Claude" reading, which also frames secret-custody as one of the four isolation axes in Agent Sandbox Architectures). OPA-in-front-of-Secrets-Manager is the provenance-as-enforcement pattern instantiated commercially. Worth a closer read of the broker's contract: what does it witness, and is the witness hash-chained.
- Aune / coding-harness eval → elenctic vibe code review + directive-proof-harness (CPRR methodology). "Measuring it, fairly" is the open question those notes exist to answer — the elenctic loop is the four-team review pattern, CPRR (Conjecture / Proof / Refutation / Revision) is the iteration discipline. Refutation surface: does the sandbox control for harness vs. model contribution, or does it conflate them?
- Poliakov / durability → caisson-style boundary work (The Four-Boundary Spec Mapping). Durable execution is the same invariant (replayable, crash-consistent witness) reached from the workflow-engine direction rather than the observation-plane direction.
- Zhu / determinism + memory → the governance tuple: a "GTM agent" that works is one where the agent decides less than the framing implies.
Open questions / TODO
[X]Date, time, venue — confirmed: Mon Jun 29 2026, 6:00–9:00pm, 355 Main Street, Cambridge MA (see Logistics).[ ]Decide priority talks for live attendance: Kumar and Aune are the two with direct refutation value to current repos.[ ]Pull Aune's sandbox repo if open-sourced; check eval methodology against the harness/model confound above.[ ]Confirm whether any talks are recorded before deciding live vs. notes-only.
Structured capture
Tangles a speaker manifest for downstream indexing.