Elenctic Vibe Code Review
Table of Contents

1. Overview
Elenctic review is a Socratic approach to examining AI-generated and vibe-coded projects. Rather than blocking agents or rewriting their output, the reviewer surfaces contradictions and violations through structured questioning.
The name comes from elenchus (ἔλεγχος) — the Socratic method of cross-examination used in Plato's early dialogues. Socrates does not teach — he questions until the interlocutor discovers contradictions in their own position. The elenctic code reviewer works the same way: the code speaks for itself; the reviewer surfaces what it reveals under examination.
2. Why This Matters
Agents that generate code are useful but risky. They bypass calculation layers, violate trust boundaries, and make changes that are difficult to audit. The code runs. The outputs look plausible. The violations are only visible through examination.
An agent asked to "build an auction calculator" will produce working code that may:
- Accept negative prices without complaint
- Return bids exceeding the item's value
- Produce different results for the same inputs depending on float ordering
- Bypass the calculation layer by calling an external API directly
These aren't bugs in the traditional sense. A prohibition-based approach blocks the agent. An elenctic approach asks: "did you mean for this to accept negative prices?"
3. The Hardening Ladder
The core model is a progressive ladder from "it works" to "it works correctly every time" — without requiring a full SDLC.
| Level | Name | What It Tests | Tools |
|---|---|---|---|
| 0 | None | Manual only | Hope |
| 1 | Examples | Specific cases | Test runner |
| 2 | Contracts | Input/output validity | Schema validator |
| 3 | Properties | Universal invariants | Property tester |
| 4 | Proofs | Mathematical certainty | Theorem prover |
Each level is additive. A project with schema validators but no tests has Level 2 artifacts but is Level 0 — the lower levels are not satisfied.
Most business applications reach Level 2 or 3. Level 4 is reserved for safety-critical or compliance domains.
3.1. Level Transitions
Each transition has one concrete action:
| From → To | Action |
|---|---|
| 0 → 1 | Write two tests: happy path + edge case. Ask: "are these right?" |
| 1 → 2 | Add assertions at boundaries for the key calculation |
| 2 → 3 | Write one property test for the strongest invariant |
| 3 → 4 | Does any rule warrant formal proof? If not, stop here |
The reviewer recommends exactly one next step. Not a roadmap. Not a refactoring plan. One action to reach the next level.
4. Five Perspectives
For each domain rule discovered in the code, the reviewer examines it from five perspectives:
4.1. Software Engineering
Does the code follow its own implied contract? Are there inputs that produce nonsensical output? Does the calculation match the domain, not just run without error?
4.2. Security
Are trust boundaries respected? Can external input reach calculations without validation? Are there side effects where pure computation was expected?
4.3. DevOps
Would this produce the same output given the same input tomorrow? Can you audit what happened after the fact? Are there implicit dependencies on environment, ordering, or state?
4.4. Operational
Could a small team deploy and run this? If something breaks in production, how would anyone know? What would an operator observe?
If the project is already deployed and accessible, a stricter lens applies: unauthenticated public endpoints are more urgent than missing tests.
4.5. Safety
Does the agent know things the application should only know? Are there leaked secrets, exposed internals, or business logic that exists only in agent instructions rather than in code? If you change the most-called function, what breaks?
5. The Review Process
The process follows a structured sequence:
- Anomaly scan. Before assessing level, scan for structural tells of agent-generated code: dead code, copy-paste with minor variations, functions 10x longer than neighbors, unused imports.
- Level assessment. Scan for artifacts (test directories, schema validators, property tests, formal specs) to determine the current hardening level.
- Rule identification. Find the business logic. Name rules R1, R2, etc. State each in plain language. Mine git history for empirical invariants — values that changed multiple times are searching for a bound.
- Five-perspective questioning. For each rule, ask from software engineering, security, DevOps, operational, and safety perspectives. Ground questions in code, not theory.
- Structured findings. Each finding includes a confidence score (0.7–1.0), the perspective that surfaced it, specific evidence, and a recommendation. Nothing below 0.7 confidence. No style preferences.
- Plain-language summary. Written for the project owner who may have built the app with AI tools. No jargon. Three concerns, one next step. Risk stated in business terms: money, time, reputation.
6. In Practice: Three Vibe-Coded Apps
To see how the process works, here are three applications built entirely with AI coding agents — each at a different hardening level, each with different review priorities. All are live on public URLs.
6.1. Ad Budget Planner (Level 0)
An advertising spend pacing tool. Calculates daily budgets, tracks ROAS, and projects campaign end dates.
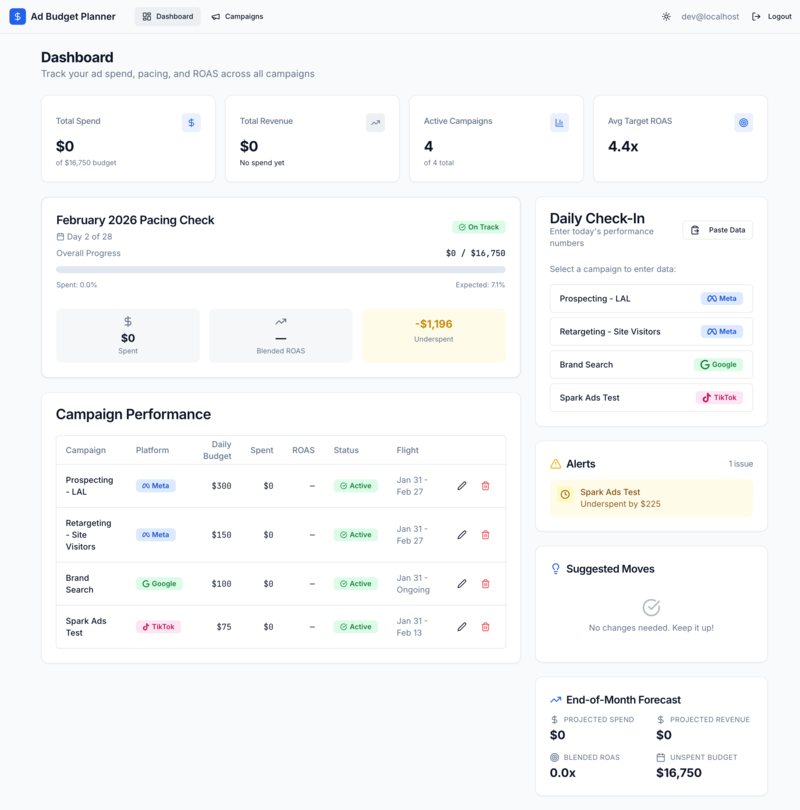
Dashboard: $16,750 budget across 4 campaigns (Meta, Google, TikTok), $0 spent on Day 2, pacing check showing -$1,196 underspent. Auth is present (dev@localhost) but the structural tells remain.
The anomaly scan reveals structural tells before looking at any business logic:
- Package name mismatch.
package.jsondeclares"name": "rest-express"— the scaffolding template was never renamed. - Phantom auth.
passportandpassport-localappear inpackage.jsondependencies but are never imported anywhere. Authentication was intended but never wired up. - Test infrastructure without tests. React components have
data-testidattributes suggesting integration testing was planned. No test runner is configured. Notests/directory exists. - 30+ unused UI packages. A full shadcn/ui install rather than selective component addition. Characteristic of agent-generated scaffolding.
The reviewer asks: "Your pacing calculation divides budget by days remaining using float division. A $10,000 campaign over 30 days accumulates rounding errors. What happens to the last $0.03?"
Next step: Add authentication — the app handles advertising budgets on a public URL.
6.2. Parlay Pal (Level 0)
A sports betting bankroll tracker. Records bets, calculates ROI, tracks exposure as a percentage of bankroll.
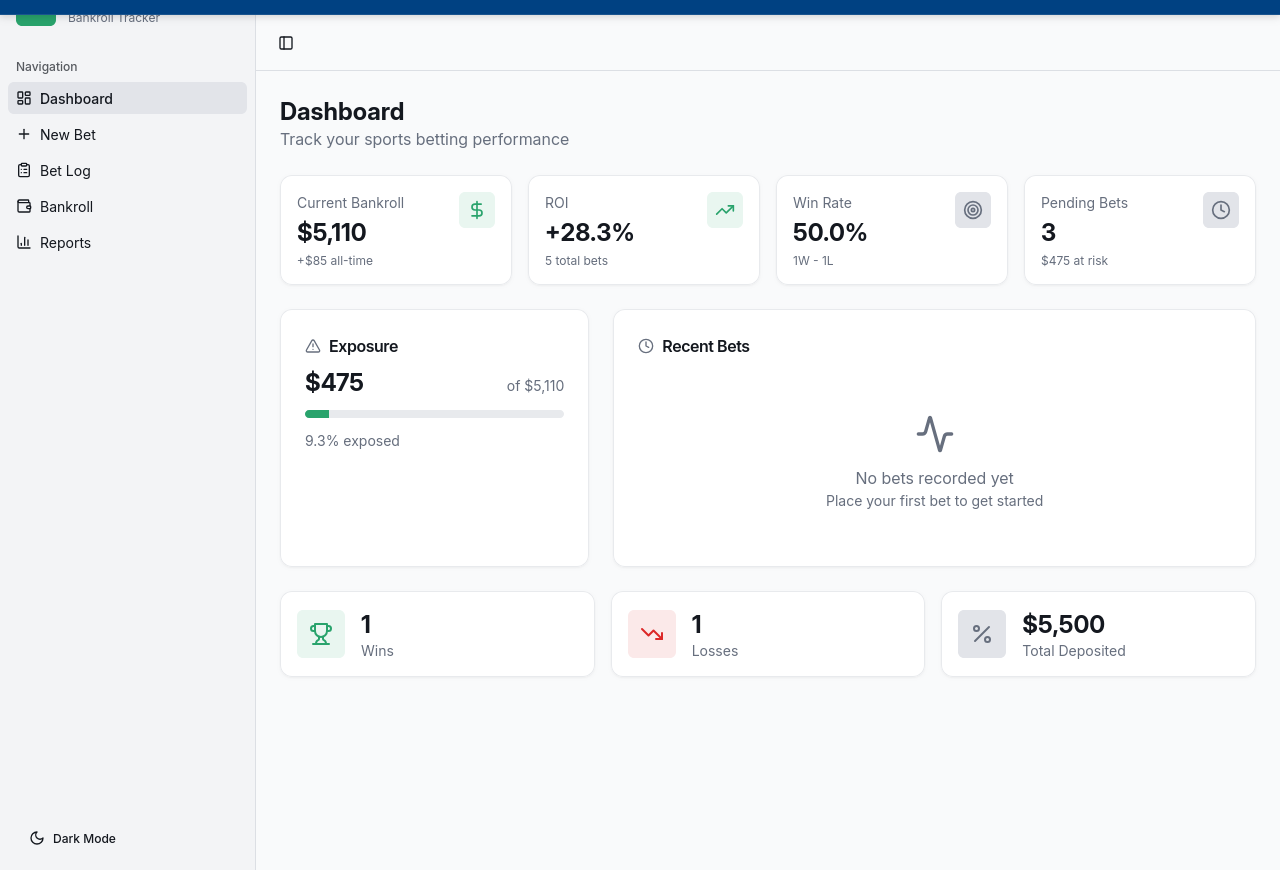
Dashboard showing $5,110 bankroll, +28.3% ROI, 50% win rate (1W-1L), and $475 exposure (9.3% of bankroll). Three pending bets at $475 risk.
The numbers are immediately interesting from a review perspective:
- ROI calculation. +28.3% ROI on 5 total bets with 1 win and 1 loss. The calculation includes unrealized gains from 3 pending bets — bets that haven't settled yet are counted as profit. "Is that how you want ROI calculated, or should pending bets be excluded?"
- Exposure tracking. $475 exposure is 9.3% of a $5,110 bankroll. But the bankroll itself includes an +$85 unrealized gain. If the pending bets lose, the real exposure is higher than displayed. "What's the exposure if all pending bets lose?"
- No bet validation. The "New Bet" form has no constraints on stake amount. A user can bet more than their bankroll. "Should the app prevent bets that exceed available bankroll minus existing exposure?"
Next step: Write two tests: one for the ROI calculation (should pending bets count?) and one for bankroll balance after a loss. These pin down the rules before the next agent session changes them.
6.3. Options Wheel Tracker (Level 2)
An options wheel strategy tracker. Monitors 16 contracts across multiple tickers, validates positions against portfolio rules, and fires alerts when invariants are violated.
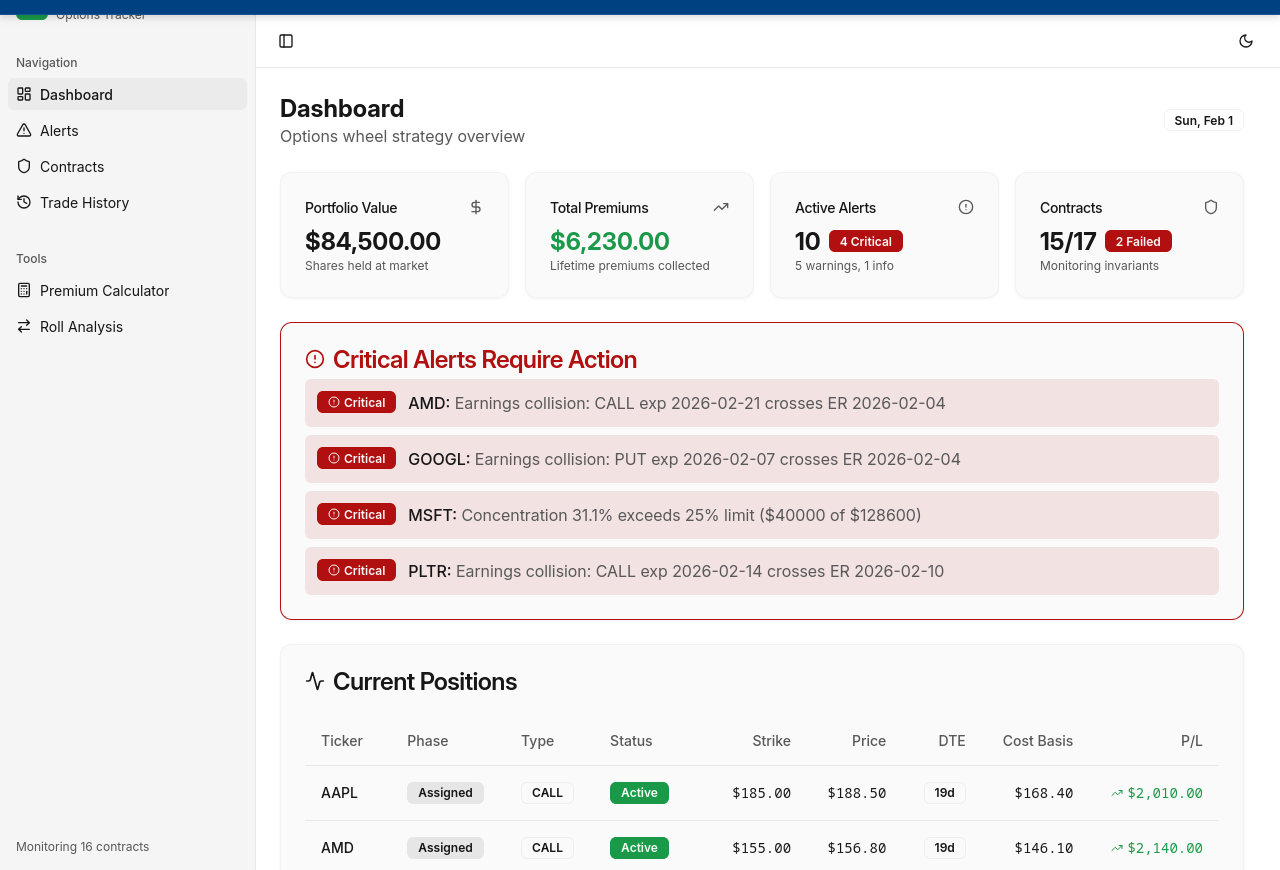
Dashboard: $84,500 portfolio, $6,230 in collected premiums, 10 active alerts (4 critical), 15 of 17 contracts passing with 2 failed invariants. Critical alerts show earnings collisions on AMD, GOOGL, PLTR and a concentration limit breach on MSFT (31.1% vs 25% max).
This is the most mature of the three. It has tests, schema validators, and a contract monitoring system that actively checks invariants. The dashboard itself reveals the review's starting points:
- The system is catching violations. 2 of 17 contract checks are failing and 4 critical alerts are firing. The monitoring infrastructure works — but what happens when an alert fires? There's no alert history or acknowledgment flow. "If you dismiss a critical alert, is that recorded anywhere?"
- Concentration limit. MSFT at 31.1% exceeds the 25% portfolio limit. The system detects it but doesn't prevent new positions that would worsen it. "Is the 25% limit a warning or a hard block? Can you still sell a new MSFT put while over the limit?"
- Float precision. All money values — strike, premium, cost basis — use
real(float32). The annualized return formula(premium/strike) × (365/DTE) × 100amplifies rounding errors. "A $0.01 error on a $50 strike becomes $7.30 annualized. Is that within your tolerance?" - Schema gap. One PATCH endpoint passes
req.bodydirectly to the database without Zod validation. Every other mutation endpoint validates. "Is this intentional or left over from an earlier iteration?"
Next step: Write a property test for the annualized return invariant (the 15% minimum threshold rule) to move toward Level 3.
6.4. What the Levels Reveal
| App | Level | First Priority | Why |
|---|---|---|---|
| Budget Planner | 0 | Security | Live, no auth, handles money |
| Parlay Pal | 0 | Software Eng | ROI includes unsettled bets |
| Wheel Tracker | 2 | Security gap | One endpoint bypasses validation |
All three are live on public URLs with no authentication. The review doesn't start with "add tests" — it starts with "who can reach this right now?" Operational and security findings take priority over engineering findings when the project is deployed.
The hardening ladder matters after the operational risk is mitigated.
7. Confidence Calibration
Not all findings are equally certain:
| Finding Type | Confidence Range |
|---|---|
| Definite bug (crashes, wrong output) | 0.95–1.0 |
| Missing contract (no validation) | 0.85–0.95 |
| Incomplete implementation | 0.75–0.90 |
| Design assumption (undocumented) | 0.70–0.80 |
| Style or best practice | < 0.70 (skip) |
The threshold exists because code review noise kills signal. Flagging style preferences alongside real issues trains the owner to ignore findings.
8. Design Principles
- Questions, not commands. "Did you mean for this to accept negative prices?" rather than "add input validation."
- Read-only. The reviewer must not change any code. This constraint is absolute. The reviewer explores and produces findings.
- Ground in code. Explore the codebase before asking open-ended questions. Prefer "this function accepts negative prices — is that intentional?" over "tell me about your validation strategy."
- One next step. The single most important action. Exception: if the project is live with an active operational risk, mitigate that first.
- Plain language for owners. "No input validation at function boundary" becomes "the app accepts values that don't make sense, like negative prices, without catching them."
- Proportional effort. Not every project needs Level 4. The question is not "should we use formal methods?" but "how much confidence do we need, and what's the cheapest way to get it?"
9. Grounding Questions
Each review perspective has a grounding question that keeps the analysis practical:
| Perspective | Grounding Question |
|---|---|
| Software Engineering | If this rule is wrong, how would anyone find out? |
| Security | Can the system tell you when it's wrong? |
| DevOps | Would the next change be safer than the last one? |
| Operational | Does this project get better over time, or just older? |
| Safety | What happens if this rule is wrong and nobody notices for a week? |
10. The Vibe Coding Landscape
The term "vibe coding" was coined by Andrej Karpathy in February 2025: "fully give in to the vibes, embrace exponentials, and forget that the code even exists." Collins Dictionary named it Word of the Year 2025.
10.1. Building Tools (Q1 2026)
| Tool | What It Is | Target User |
|---|---|---|
| Claude Code | Terminal agent, multi-file orchestration | Developers |
| Claude Cowork | File/document agent, no code required | Non-technical |
| Cursor | IDE with AI-native editing | Developers |
| Replit Agent | Browser IDE, deploy from chat | Non-technical |
| Gemini CLI | Terminal agent, 1M token context | Developers |
| Kiro (AWS) | Spec-driven agentic IDE | Developers |
10.2. Examination Tools
| Tool | Checks |
|---|---|
| Vale | Prose quality in specs and docs |
| TLA+ | State machine invariants |
| Lean 4 | Theorem proving for critical properties |
| Z3/cvc5 | Constraint satisfaction, SMT verification |
The gap: building tools produce code fast, examination tools verify it slowly. The elenctic process bridges this by using whatever tools are available and asking questions when they surface violations.
11. Related Work
- Karpathy, Andrej. "Vibe Coding" (original tweet). February 2025.
- Kim, Gene and Steve Yegge. Vibe Coding: Building Production-Grade Software With GenAI. IT Revolution, October 2025.
- Yegge, Steve. "Revenge of the Junior Developer". Sourcegraph, March 2025.
- Willison, Simon. "Not all AI-assisted programming is vibe coding". March 2025.
- Osmani, Addy. Beyond Vibe Coding. 2025.
- Kleppmann, Martin. "AI will make formal verification go mainstream". December 2025.
- Bacchelli and Bird. "Expectations, Outcomes, and Challenges of Modern Code Review". ICSE 2013.
- Lakatos, Imre. Proofs and Refutations. Cambridge University Press, 1976.
- Wayne, Hillel. Practical TLA+: Planning Driven Development. Apress, 2018.
- Meyer, Bertrand. Object-Oriented Software Construction. 2nd ed., Prentice Hall, 1997.
12. See Also
- TLA+ for System Design — formal specification at Level 3–4
- Lean 4 on FreeBSD 15.0 — theorem proving at Level 4
- Agentic Systems Q1 2026 — the agent ecosystem under examination