Latent Configuration: When Deploy != Activate
A Case Study in Dormant Misconfigurations
Table of Contents
- 1. Abstract
- 2. The Incident
- 3. Taxonomy of Latent Configuration
- 4. The SO_REUSEADDR Complication
- 5. Detection Strategies
- 6. Remediation Patterns
- 7. Historical Precedents
- 8. Theoretical Foundations
- 9. Historical Evolution of Configuration Management
- 10. Academic Context
- 11. Operational Recommendations
- 12. Lessons Learned
- 13. Appendix: Full Diagnostic Session
- 14. References

1. Abstract
Configuration changes that don't take effect until an unrelated event (restart, upgrade, failover) represent a distinct failure mode in systems administration. This pattern—"latent configuration"—creates temporal separation between cause and effect, complicating root cause analysis and often triggering incidents during unrelated maintenance windows.
This article documents a real-world case where a misconfigured telemetry service lay dormant for 78 days before activating during a FreeBSD upgrade, silently breaking an ADS-B data collection system.
2. The Incident
2.1. Timeline
| Date | Event | Impact |
|---|---|---|
| Dec 26, 2025 | sbs-logger deployed, connects to localhost:30003 | Working |
| Apr 4, 2026 | telegraf.conf committed with socket_listener:30003 | None (pkg not installed) |
| Apr 4 - Jun 21 | Config exists in repo, telegraf package missing | System works correctly |
| Jun 21, 2026 18:24:41 | FreeBSD 14.4 upgrade installs dump1090 | - |
| Jun 21, 2026 18:24:55 | FreeBSD 14.4 upgrade installs telegraf | Conflict activated |
| Jun 22-26, 2026 | ADS-B data collection fails silently | 5 days data loss |
| Jun 27, 2026 | Root cause identified and fixed | Resolved |
2.2. The Configuration Error
The telegraf configuration intended to ingest ADS-B data from dump1090:
# telegraf.conf - April 4, 2026
[[inputs.socket_listener]]
service_address = "tcp://127.0.0.1:30003"
data_format = "csv"
csv_column_names = ["message_type", "transmission_type", ...]
name_prefix = "adsb_"
The error: socket_listener listens on a port, waiting for data to be
pushed. But dump1090 also listens on port 30003, expecting clients to
connect and pull data. Neither service connects to the other—both are
servers.
2.3. The Masking Mechanism
The configuration sat dormant because:
- The config file was committed to the repository
- The telegraf package was not installed on the target system
- No CI/CD pipeline validated that referenced packages exist
- The system appeared healthy during manual verification
2.4. The Activation Trigger
During the FreeBSD 14.4 upgrade:
$ pkg query '%n %t' | grep -E "dump1090|telegraf"
dump1090 1782080681 # Jun 21 18:24:41
telegraf 1782080695 # Jun 21 18:24:55
Both packages installed within 14 seconds. On service start:
- dump1090 binds to
*:30003(wildcard) - telegraf binds to
127.0.0.1:30003(specific) SO_REUSEADDRallows both bindings to succeed- Kernel routes localhost connections to more specific binding
- sbs-logger connects to localhost:30003 → reaches telegraf, not dump1090
2.5. The Silent Failure
No errors appeared because:
- Both services started successfully
- Port binding succeeded for both (
SO_REUSEADDR) - sbs-logger connected successfully (to the wrong service)
- Telegraf accepted connections (waiting for CSV data that never came)
- No health check verified actual data flow
3. Taxonomy of Latent Configuration
3.1. Definition
Latent Configuration: A configuration change that exists in the declared state but does not affect the running state until an activation event occurs.
3.2. Related Patterns
3.2.1. Configuration Drift (Inverse Problem)
Running state diverges from declared state over time. Manual changes accumulate. A restart reveals the drift by applying the declared state.
Configuration Drift: Declared: service_port=8080 Running: service_port=9090 (manual change) Restart: Port reverts to 8080, breaks clients Latent Configuration: Declared: new_feature=true Running: new_feature=false (package not installed) Upgrade: Feature activates, breaks dependencies
3.2.2. Dark Launch / Dark Deploy
Intentional pattern: deploy code but don't activate it. Feature flags control activation. Latent configuration is the unintentional version.
3.2.3. Restart Lottery
Who gets paged when latent configuration activates? Often not the person who wrote it. The activation event (upgrade, failover, restart) is temporally and causally disconnected from the configuration change.
3.3. Failure Mode Classification
| Type | Declared State | Running State | Activation |
|---|---|---|---|
| Dormant Config | Config exists | Service not running | Service start |
| Missing Package | Config references pkg | Package not installed | Package install |
| Feature Flag | Flag set | Code path disabled | Flag flip |
| Schema Migration | Migration file exists | DB unchanged | Migration run |
| DNS Propagation | Record updated | Cached value in use | TTL expiry |
4. The SO_REUSEADDR Complication
4.1. Standard Behavior
Normally, binding to an in-use port fails:
# Process A binds to *:30003
# Process B tries to bind to *:30003
# Result: OSError: [Errno 98] Address already in use
4.2. With SO_REUSEADDR
import socket
# Process A: dump1090 on *:30003
s1 = socket.socket()
s1.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s1.bind(('0.0.0.0', 30003)) # Success
# Process B: telegraf on 127.0.0.1:30003
s2 = socket.socket()
s2.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s2.bind(('127.0.0.1', 30003)) # Also succeeds!
# Connection routing: more specific wins
# localhost:30003 → 127.0.0.1:30003 (telegraf)
# external:30003 → 0.0.0.0:30003 (dump1090)
4.3. Verification
$ sockstat -4 -l | grep 30003
root dump1090 25905 9 tcp4 *:30003 *:*
telegraf telegraf 17031 5 tcp4 127.0.0.1:30003 *:*
The kernel's address specificity routing created a silent shadow binding.
5. Detection Strategies
5.1. Pre-Deploy Validation
#!/bin/sh
# check-config-deps.sh
# Verify all config-referenced packages are installed
config_file="$1"
missing=0
for pkg in $(grep -oE 'inputs\.[a-z_]+' "$config_file" | cut -d. -f2 | sort -u); do
if ! pkg info -e "$pkg" 2>/dev/null; then
if ! pkg info -e "telegraf" 2>/dev/null; then
echo "WARNING: config references $pkg but telegraf not installed"
missing=1
fi
fi
done
exit $missing
5.2. Port Conflict Detection
#!/bin/sh
# check-port-conflicts.sh
# Detect multiple processes on same port
conflicts=$(sockstat -4l | awk 'NR>1 {print $6}' | \
grep -oE ':[0-9]+$' | sort | uniq -d)
if [ -n "$conflicts" ]; then
echo "Port conflicts detected:"
for port in $conflicts; do
echo " $port:"
sockstat -4l | grep "$port"
done
exit 1
fi
5.3. Startup Order Verification
#!/bin/sh
# verify-service-ports.sh
# Run after service start, verify expected process owns port
check_port_owner() {
port=$1
expected_proc=$2
actual=$(sockstat -4l | grep ":$port " | awk '{print $2}' | head -1)
if [ "$actual" != "$expected_proc" ]; then
echo "ERROR: Port $port owned by $actual, expected $expected_proc"
return 1
fi
}
check_port_owner 30003 dump1090
check_port_owner 8086 influxd
5.4. Continuous Monitoring
# monit configuration
check program port-30003-owner with path "/usr/local/bin/check-port-owner 30003 dump1090"
every 5 cycles
if status != 0 then alert
6. Remediation Patterns
6.1. Principle: Config Should Fail Loudly
Don't silently accept incorrect state. If telegraf can't ingest from dump1090, it should fail to start or emit errors.
6.2. Anti-Pattern: Silent Accept
# BAD: Listens on port, accepts connections, discards non-CSV data
[[inputs.socket_listener]]
service_address = "tcp://127.0.0.1:30003"
6.3. Pattern: Explicit Connection
# BETTER: Use a plugin that CONNECTS to dump1090
# (Note: telegraf doesn't have this - need external tool)
[[inputs.exec]]
commands = ["nc localhost 30003 | head -100"]
timeout = "10s"
data_format = "csv"
6.4. Pattern: Data Flow Verification
# BEST: Verify actual data, not just connectivity
[[inputs.tail]]
files = ["/mnt/usb/adsb/raw/latest.csv"]
data_format = "csv"
# If file not updating, monitoring catches it
7. Historical Precedents
7.1. The Five-State Synchronization Problem
In traditional server administration, configuration exists in multiple places:
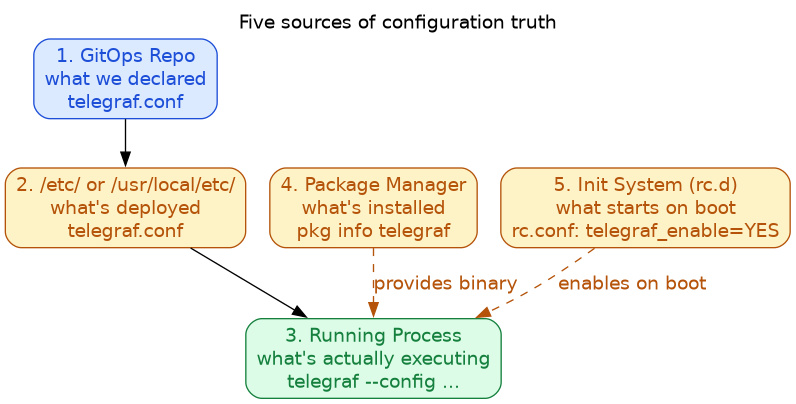
Our incident involved desync between states 1, 4, and 5:
| State | Value | Sync Status |
|---|---|---|
| GitOps | telegraf.conf exists | Committed Apr 4 |
| etc | telegraf.conf deployed | Copied manually |
| Running | telegraf not running | Package missing |
| Package | telegraf not installed | Not in pkg list |
| rc.conf | telegraf_enable="YES" | Set but no effect |
7.2. The Cattle vs Pets Principle
Popularized by Randy Bias (2012), later adopted by CNCF:
"In the old way of doing things, we treat our servers like pets… We give them names like Zeus, Hera, or perhaps mail1, mail2… In the new way, servers are numbered, like cattle in a herd."
7.2.1. Pets (Our Failure Mode)
- Long-lived servers accumulate state
- Manual configuration changes persist
- Upgrades reveal latent misconfigurations
- Debugging requires archaeology
# Hydra has 847 days of accumulated uptime (running since early 2024)
$ uptime
9:03PM up 847 days, 12:34
# Config changes from 2+ years ago may still be latent
7.2.2. Cattle (Prevention)
- Servers are ephemeral and replaceable
- All state comes from declared configuration
- No latent config—each boot applies current state
- Failures are remediated by replacement, not repair
# Kubernetes approach: pod restart applies new config immediately
$ kubectl rollout restart deployment/telegraf
7.3. GitOps: The Intended Solution
GitOps (Weaveworks, 2017) establishes Git as the single source of truth:
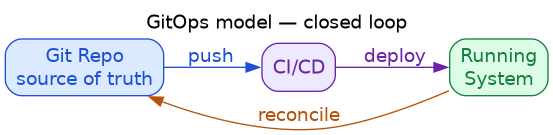
Key properties: Git is the only source of truth; continuous reconciliation detects drift; changes are atomic (config + package + enable).
7.3.1. What GitOps Would Have Caught
If we had proper GitOps reconciliation:
# Desired state in Git
telegraf:
package: installed
config: /usr/local/etc/telegraf.conf
enabled: true
running: true
# Reconciliation would fail on Apr 4:
# ERROR: telegraf.config declared but telegraf.package not installed
# ERROR: telegraf.enabled but telegraf service not found
7.3.2. Why It Failed For Us
- Partial GitOps: Config in Git, but package state not declared
- No reconciliation loop: Manual deployment, no drift detection
- Deferred activation: rc.conf enables a service that doesn't exist yet
7.4. Historical Examples
7.4.1. Knight Capital (2012) — $440M in 45 Minutes
Old trading code was left on one of eight servers during deployment. When activated, it executed obsolete trading logic at high speed.
- Pattern: Deploy to 7/8 servers; 8th had latent old config
- Activation: Market open triggered code path
- Damage: $440M loss, company sold
7.4.2. Amazon S3 Outage (2017)
A typo in a manual command removed more servers than intended. The playbook hadn't been tested against current fleet size.
- Pattern: Manual runbook diverged from automation
- Activation: Human execution of stale procedure
- Damage: 4-hour outage, cascading AWS failures
7.4.3. Cloudflare (2019) — Regex Backtracking
A WAF rule update caused catastrophic backtracking. The rule had been in the repo for weeks but wasn't deployed.
- Pattern: Staged deployment with manual promotion
- Activation: Global deploy of accumulated changes
- Damage: 27-minute global outage
7.4.4. GitLab Database Deletion (2017)
A sysadmin ran the wrong command on the wrong server. Backup procedures had been documented but not tested.
- Pattern: Documented config vs actual config divergence
- Activation: Manual intervention during incident
- Damage: 6 hours data loss, 18 hours to recover
7.5. Lessons from History
| Incident | Latent Period | Activation Trigger | Root Cause |
|---|---|---|---|
| Knight Capital | Unknown | Market open | Partial deployment |
| Amazon S3 | Unknown | Manual runbook | Stale automation |
| Cloudflare | Weeks | Global promotion | Staged deploy |
| GitLab | Unknown | Incident response | Untested backups |
| Our ADS-B | 78 days | Package upgrade | Config without pkg |
Common thread: Declared state ≠ Running state, with delayed reconciliation.
8. Theoretical Foundations
8.1. Promise Theory and Convergence (Burgess, 1993-2004)
Mark Burgess introduced CFEngine in 1993, establishing the theoretical foundation for modern configuration management. His key insight was convergence: systems should automatically adjust themselves to reach and maintain a desired state.
"What CFEngine's convergent end-state, and later promise theory, were able to do was to redefine a change process as the assurance of a system of fixed outcomes (targets), based entirely on data—the description of the absolute state rather than a sequence of relative transformations." — Mark Burgess
8.1.1. Convergence vs. Idempotence
Burgess distinguishes these concepts:
- Idempotence: Running an operation multiple times produces the same result as running it once (f(f(x)) = f(x))
- Convergence: The system moves toward a desired end-state from any initial state, self-repairing broken parts
Our incident violated convergence: the system could not self-repair because the repair mechanism (telegraf) was not installed.
8.1.2. Promise Theory (2004)
Burgess formalized autonomous system cooperation in "promise theory":
A promise is a declaration of intent by an autonomous agent. Agent A promises Agent B to maintain property P. Key properties: - Voluntary: agents cannot be forced to keep promises - Local: agents only control their own behavior - Verifiable: outcomes can be checked independently
In our incident, the telegraf configuration file made a promise ("I will listen on port 30003") that could not be kept because the promising agent (telegraf service) did not exist.
8.2. Desired State vs. Actual State
The fundamental model of configuration management:

8.2.1. Declarative vs. Imperative
| Approach | Description | Tool Examples |
|---|---|---|
| Declarative | Define end state; tool determines steps | Puppet, Terraform |
| Imperative | Define sequence of steps to execute | Chef, Shell scripts |
Declarative tools detect drift by comparing desired to actual state. Imperative tools cannot—they only know what steps to run, not what state should exist.
8.3. Eventual Consistency in Configuration
Borrowed from distributed systems theory (Vogels, 2009):
"Eventual consistency: if no new updates occur, all nodes will eventually converge to the same state."
Applied to configuration management:
- Strong consistency: Every configuration change is immediately reflected in running state (requires restart or live reload)
- Eventual consistency: Configuration changes propagate asynchronously; system converges over time
Our incident was a failure of eventual consistency: the configuration was deployed but never converged to running state because the reconciliation mechanism (package installation) was missing.
8.4. The Reconciliation Loop
GitOps and Kubernetes formalized the continuous reconciliation pattern:
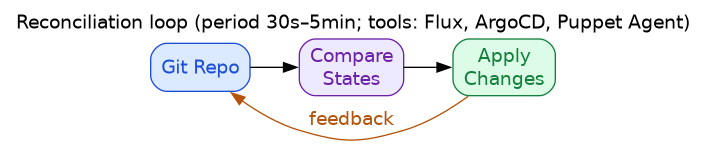
The reconciliation loop assumes all components exist. Our failure: the loop never ran because telegraf wasn't installed to be reconciled.
9. Historical Evolution of Configuration Management
9.1. Timeline
| Year | Event | Significance |
|---|---|---|
| 1993 | CFEngine 1.0 | First convergent configuration tool |
| 2004 | Promise Theory | Formal model of autonomous cooperation |
| 2005 | Puppet | Enterprise CM with declarative DSL |
| 2008 | CFEngine 3 | Promise theory integration |
| 2009 | Chef | Ruby-based imperative CM |
| 2011 | Cattle vs Pets | Randy Bias names the paradigm shift |
| 2012 | Ansible | Agentless, SSH-based CM |
| 2013 | Docker | Immutable containers emerge |
| 2014 | Kubernetes | Container orchestration |
| 2017 | GitOps | Weaveworks formalizes Git-centric ops |
| 2019 | Flux/ArgoCD | GitOps reconciliation tools mature |
9.2. The Cattle vs. Pets Paradigm (Bias, 2011-2012)
Randy Bias popularized this analogy, originally from Bill Baker's SQL Server scaling presentation:
"In the old way of doing things, we treat our servers like pets… We give them names like Zeus, Hera, or perhaps mail1, mail2… In the new way, servers are numbered, like cattle in a herd." — Randy Bias, 2012
9.2.1. Implications for Latent Configuration
| Paradigm | Server Lifespan | Config Accumulation | Latent Bugs |
|---|---|---|---|
| Pets | Years | High | Many |
| Cattle | Hours/Days | None | Impossible |
Cattle eliminate latent configuration: each instance boots fresh, applying current declared state. There is no gap for configuration to become latent.
Our hydra server is a pet (847 days uptime), accumulating configuration changes that may not activate until the next reboot or upgrade.
9.3. Tool-Specific Behaviors and Failure Modes
Each configuration management tool handles the latent configuration problem differently. Understanding these differences explains why our incident occurred and how it might have been prevented.
9.3.1. Puppet: Catalog Compilation and Agent Reconciliation
Puppet uses a two-phase model:
- Compile phase (on master): Generate catalog from manifests
- Apply phase (on agent): Enforce catalog on target node
# Puppet manifest - telegraf.pp
package { 'telegraf':
ensure => installed,
}
file { '/usr/local/etc/telegraf.conf':
ensure => file,
source => 'puppet:///modules/telegraf/telegraf.conf',
require => Package['telegraf'], # Explicit dependency
}
service { 'telegraf':
ensure => running,
enable => true,
require => [Package['telegraf'], File['/usr/local/etc/telegraf.conf']],
}
How Puppet would have caught our bug:
- The
require => Package['telegraf']dependency means the file resource won't be applied until the package is installed - The Puppet agent checks every 30 minutes and would report drift
- If the package isn't installed, the catalog application fails loudly
Puppet's limitation:
If the manifest is committed but never applied (no Puppet agent running), the configuration remains latent—exactly our scenario.
9.3.2. Ansible: Imperative Execution with State Checks
Ansible executes tasks sequentially in a playbook:
# playbook.yml
- name: Configure telegraf
hosts: hydra
tasks:
- name: Install telegraf
ansible.builtin.package:
name: telegraf
state: present
- name: Deploy telegraf config
ansible.builtin.copy:
src: telegraf.conf
dest: /usr/local/etc/telegraf.conf
notify: restart telegraf
- name: Ensure telegraf is running
ansible.builtin.service:
name: telegraf
state: started
enabled: yes
handlers:
- name: restart telegraf
ansible.builtin.service:
name: telegraf
state: restarted
How Ansible would have caught our bug:
- Tasks execute in order; config deployment follows package installation
- If package installation fails, subsequent tasks fail
- Running
ansible-playbook --checkperforms dry-run validation
Ansible's limitation:
Ansible is push-based, not pull-based. If you deploy config files manually
(as we did with cp) without running the playbook, Ansible has no
reconciliation loop to detect drift. The config sits latent until the
next playbook run.
"Poor dependency handling is the number one cause of flaky, intermittent failures in large-scale Ansible playbooks." — Ansible best practices documentation
9.3.3. Terraform: Plan/Apply with State Tracking
Terraform maintains explicit state and requires plan before apply:
# main.tf
resource "freebsd_pkg" "telegraf" {
name = "telegraf"
}
resource "local_file" "telegraf_config" {
filename = "/usr/local/etc/telegraf.conf"
content = file("${path.module}/telegraf.conf")
depends_on = [freebsd_pkg.telegraf]
}
resource "freebsd_service" "telegraf" {
name = "telegraf"
enabled = true
running = true
depends_on = [local_file.telegraf_config]
}
How Terraform would have caught our bug:
terraform plancompares desired state to actual infrastructure- If telegraf package isn't installed, plan shows it needs to be created
- Running
terraform plan -refresh-onlydetects drift without proposing changes
Terraform's drift detection:
$ terraform plan -refresh-only
Refreshing state...
Note: Objects have changed outside of Terraform
Terraform detected the following changes made outside of Terraform
since the last "terraform apply":
# freebsd_pkg.telegraf has been deleted
- resource "freebsd_pkg" "telegraf" {
- name = "telegraf" -> null
}
Terraform's limitation:
Terraform only knows about resources it manages. If you create a config
file outside Terraform (manual cp or another tool), Terraform's state
file doesn't track it. The file is invisible to drift detection.
"Terraform plan only compares the current state file with your configuration and doesn't always check what's really deployed." — HashiCorp Documentation
9.3.4. Chef: Two-Pass Compile/Converge Model
Chef has a notorious two-phase execution model:
- Compile phase: Ruby code executes, building resource collection
- Converge phase: Resources are applied to the system
# recipe/telegraf.rb
package 'telegraf' do
action :install
end
template '/usr/local/etc/telegraf.conf' do
source 'telegraf.conf.erb'
notifies :restart, 'service[telegraf]'
end
service 'telegraf' do
action [:enable, :start]
end
Classic Chef convergence bug:
# WRONG: File.exist? runs at COMPILE time, before package is installed
package 'telegraf'
if File.exist?('/usr/local/bin/telegraf')
template '/usr/local/etc/telegraf.conf' do
source 'telegraf.conf.erb'
end
end
The File.exist? check runs during compile phase, before the package
resource executes. The file doesn't exist yet, so the template is never
added to the resource collection.
Correct pattern:
# RIGHT: only_if runs at CONVERGE time
template '/usr/local/etc/telegraf.conf' do
source 'telegraf.conf.erb'
only_if { ::File.exist?('/usr/local/bin/telegraf') }
end
How Chef would have caught our bug:
- Chef-client runs periodically (like Puppet agent)
- Resources with dependencies fail if dependencies aren't met
- Chef's
why-runmode (like Ansible's--check) shows what would change
Chef's limitation:
If Chef isn't running on the node, or if the cookbook is never applied, configuration remains latent.
9.3.5. Comparison Matrix
| Tool | Execution Model | Drift Detection | Reconciliation | Our Bug Would… |
|---|---|---|---|---|
| Puppet | Pull (agent) | Every 30 min | Automatic | Fail on missing package dependency |
| Ansible | Push (playbook) | Manual/scheduled | On playbook run | Not run if playbook not executed |
| Terraform | Plan/Apply | plan -refresh-only |
On apply | Show missing package in plan |
| Chef | Pull (client) | Every 30 min | Automatic | Fail on missing package |
| None (manual) | Ad-hoc | None | None | Remain latent indefinitely |
9.3.6. The Common Failure Mode
All tools share one vulnerability: they must be running to detect drift.
| Scenario | Result |
|---|---|
| Config committed to Git, tool not installed | Latent |
| Config deployed to etc, agent not running | Latent |
| Config in state file, infrastructure deleted | Detected on next run |
| Config file exists, referenced package missing | Depends on tool |
Our incident fell into the first category: telegraf.conf was committed to Git, but telegraf package wasn't installed. No tool was running to detect the discrepancy.
9.4. GitOps: Formalizing the Solution (Richardson, 2017)
Alexis Richardson of Weaveworks coined "GitOps" to describe their operational methodology:
"GitOps is a way of implementing Continuous Deployment for cloud native applications. It focuses on a developer-centric experience when operating infrastructure, by using tools developers are already familiar with, including Git and Continuous Deployment tools." — Alexis Richardson, 2017
9.4.1. Core Principles
- Git as single source of truth: All desired state in version control
- Declarative descriptions: Describe what, not how
- Automated reconciliation: Agents continuously sync actual to desired
- Closed loop: Changes only through Git, never direct mutation
9.4.2. What GitOps Would Prevent
In a proper GitOps setup, our incident could not occur:
# GitOps manifest would declare the full stack
telegraf:
package:
state: installed
version: "1.31.0"
service:
state: running
enabled: true
config:
source: telegraf.conf
ports:
- 8125/udp # StatsD
- 8092/udp # Influx Line Protocol
# NOTE: Never 30003 - reserved for dump1090 SBS
The reconciliation agent would fail immediately if the package was not installed, rather than silently deploying configuration for a non-existent service.
10. Academic Context
10.1. Empirical Studies on Configuration Errors
10.1.1. Yin et al. (SOSP 2011)
"An Empirical Study on Configuration Errors in Commercial and Open Source Systems" analyzed 546 real-world configuration errors:
- 70.0%–85.5% are mistakes in setting configuration parameters
- 38.1%–53.7% of parameter mistakes are illegal parameters that violate format or rules
- 12.2%–29.7% are inconsistencies between parameter values
- Configuration errors account for a significant portion of production system failures
Key finding relevant to our incident: many configuration errors are latent until a specific trigger activates the misconfigured code path.
10.1.2. Xu et al. (SOSP 2013)
"Do Not Blame Users for Misconfigurations" argues that software developers should take active responsibility for configuration errors:
"Configuration errors are one of the major causes of today's system failures… These issues leave users clueless and forced to report to developers for technical support."
The paper proposes generating misconfigurations based on constraints inferred from source code—essentially fuzzing configuration space.
10.1.3. Xu et al. (OSDI 2016)
"Early Detection of Configuration Errors" monitors system metrics to catch misconfigurations before they cause major failures. The approach analyzes metric patterns to flag bad configurations like memory limits and thread pool sizes.
10.2. Configuration Smells (Sharma et al.)
Analogous to code smells, configuration smells indicate potential problems:
| Smell | Description | Our Instance |
|---|---|---|
| Dead Code | Unreachable config | Config without package |
| Duplicate Values | Same value in multiple places | Port 30003 in two configs |
| Inconsistent Naming | Similar concepts named differently | — |
| Magic Numbers | Hardcoded values without context | Port 30003 without comment |
| Shadowed Config | Later config overrides earlier | telegraf shadows dump1090 |
10.3. Related Reading
Tianyin Xu maintains a comprehensive reading list of configuration management papers: tianyin/configuration-management-papers
10.4. Chaos Engineering as Detection
Netflix's Chaos Engineering approach to latent configuration:
- Terminate random instances: Forces configuration activation
- Inject network partitions: Reveals failover configuration
- Corrupt state: Validates recovery procedures
"If you want to find latent configuration bugs, force restarts." — Chaos Engineering principle
The insight: latent configuration survives because systems run too long. Introducing controlled chaos—random restarts, instance replacement, failure injection—flushes latent state to the surface where it can be detected and fixed before an uncontrolled activation event (like our FreeBSD upgrade) causes an outage.
11. Operational Recommendations
11.1. The Sync Invariant
Maintain this invariant at all times:
GitOps Repo = /etc/ = Running State = Package State = Init State
Any desync should be:
- Detected immediately (monitoring)
- Alerted loudly (not silent)
- Resolved before the next change
11.2. Checklist: Before Committing Service Config
- [ ] Package is installed on target system
- [ ] Service is enabled in rc.conf/systemd
- [ ] Port numbers don't conflict with existing services
- [ ] Config has been tested with `service X configtest`
- [ ] Dry-run deployment shows expected changes only
- [ ] Rollback procedure is documented and tested
11.3. Checklist: Before System Upgrade
- [ ] Compare installed packages with GitOps-declared packages
- [ ] Check for config files in repo that reference missing packages
- [ ] Verify port assignments across all declared services
- [ ] Identify services that will be installed/upgraded
- [ ] Review rc.conf entries against installed packages
- [ ] Test upgrade on staging with full service restart
11.4. Monitoring Recommendations
# monit: Verify process owns expected port
check program dump1090-port-owner
with path "/usr/local/bin/check-port-owner 30003 dump1090"
if status != 0 then alert
# monit: Detect any port conflicts
check program port-conflicts
with path "/usr/local/bin/detect-port-conflicts"
if status != 0 then alert
# monit: Verify data flow, not just process health
check file adsb-data-fresh
with path /mnt/usb/adsb/raw/latest.csv
if timestamp > 5 minutes then alert
11.5. The Nuclear Option: Immutable Infrastructure
Eliminate latent configuration entirely:
- Never patch running systems
- Build new images with complete state
- Deploy by replacing, not updating
- All state is ephemeral or externalized
# Instead of:
pkg upgrade && service telegraf restart
# Do:
packer build freebsd-hydra.pkr.hcl
terraform apply # Replaces instance
12. Lessons Learned
12.1. For This Incident
- Port 30003 is a well-known ADS-B port; don't reuse it
socket_listenervssocket_readersemantics matter- Package installation should be part of config deployment
- Silent failures need data flow verification, not just connectivity
12.2. General Principles
- Minimize the deploy-activate gap: Config should take effect immediately or fail loudly
- Validate dependencies at deploy time: If config references a package, verify the package exists
- Test activation, not just deployment: CI should include restart cycles
- Monitor data flow, not just service health: A running service isn't necessarily a working service
- Document well-known ports: 30003 (SBS), 30005 (Beast), 8080 (HTTP) should be reserved explicitly
13. Appendix: Full Diagnostic Session
13.1. Initial Symptom
$ wc -l /mnt/usb/adsb/raw/2026/06/*/sbs*.csv.gz
2942029 Jun 20
2518582 Jun 21 # Last good day
24 Jun 22 # Header only
24 Jun 23
24 Jun 24
24 Jun 25
13.2. Root Cause Identification
$ sockstat -4 -l | grep 30003
root dump1090 25905 9 tcp4 *:30003 *:*
telegraf telegraf 17031 5 tcp4 127.0.0.1:30003 *:*
$ pkg query '%t' dump1090 telegraf
1782080681 # Jun 21 18:24:41
1782080695 # Jun 21 18:24:55
13.3. Fix Applied
- [[inputs.socket_listener]]
- service_address = "tcp://127.0.0.1:30003"
+ # DISABLED: socket_listener conflicts with dump1090:30003
+ # Use tail plugin on sbs-logger files instead
+ # [[inputs.socket_listener]]
+ # service_address = "tcp://127.0.0.1:30003"
14. References
14.1. Foundational Theory
- Burgess, M. (1995). "A Site Configuration Engine." Computing Systems, 8(3). Mark Burgess Website
- Burgess, M. (2004). "Some Notes About Promise Theory and How to Apply It to Systems." Promise Theory Method (PDF)
- Burgess, M. (2015). Thinking in Promises: Designing Systems for Cooperation. O'Reilly Media. ISBN 978-1491917879.
14.2. Empirical Studies
- Yin, Z., Ma, X., Zheng, J., Zhou, Y., Bairavasundaram, L.N., & Pasupathy, S. (2011). "An Empirical Study on Configuration Errors in Commercial and Open Source Systems." SOSP '11, pp. 159-172. SOSP Paper (PDF)
- Xu, T., Zhang, J., Huang, P., Zheng, J., Sheng, T., Yuan, D., Zhou, Y., & Pasupathy, S. (2013). "Do Not Blame Users for Misconfigurations." SOSP '13, pp. 244-259. ACM Digital Library
- Xu, T., et al. (2016). "Early Detection of Configuration Errors to Reduce Failure Damage." OSDI '16.
- Recent survey: "Rethinking Software Misconfigurations in the Real World: An Empirical Study and Literature Analysis." arXiv:2412.11121 (2024). arXiv Paper
14.3. Configuration Management Reading List
- Xu, T. "Configuration Management Papers." GitHub Repository
14.4. Paradigm Shifts
- Bias, R. (2012). "The History of Pets vs Cattle and How to Use the Analogy Properly." Cloudscaling Blog
- Richardson, A. (2017). "What Is GitOps Really?" Weaveworks Blog
- Schapiro, S. (2021). "How Did GitOps Get Started? An Interview with Alexis Richardson." Interview
14.5. Infrastructure Drift
- Spacelift. "Infrastructure Drift Detection and Reconciliation." Spacelift Documentation
- "Automated Cloud Infrastructure-as-Code Reconciliation with AI Agents." arXiv:2510.20211 (2025). arXiv Paper
14.6. Chaos Engineering
- Basiri, A., et al. (2016). "Chaos Engineering." IEEE Software, 33(3).
- Allspaw, J. (2010). Web Operations: Keeping the Data on Time. O'Reilly Media.
14.7. Historical Incidents
- SEC. (2013). "In the Matter of Knight Capital Americas LLC." Administrative Proceeding File No. 3-15570.
- Amazon. (2017). "Summary of the Amazon S3 Service Disruption." AWS Post-Mortem
- Cloudflare. (2019). "Details of the Cloudflare outage on July 2, 2019." Cloudflare Blog
- GitLab. (2017). "Postmortem of database outage of January 31." GitLab Blog