Walsh-Research Bot Compliance Specification
Table of Contents
- 1. Status
- 2. How to use this document
- 3. Conformance language
- 4. Versioning and identity
- 5. Canonical resources
- 6. Normative constants
- 7. Pre-request gate
- 8. Identity — R1
- 9. Pre-request gates — R2, R3, R4, R5
- 10. Scope and data-handling limits — R6, R7, R8, R9
- 11. Caching and persistence — R10, R11, R12
- 12. Conformance test vectors
- 12.1. robots.txt group selection (token
Walsh-Research) - 12.2. robots.txt path matching (within the selected group)
- 12.3. Blocklist domain matching (listed domain
example.com) - 12.4. URL canonicalization (for dedup)
- 12.5. Retry-After parsing (now =
Mon, 23 May 2026 00:00:00 GMT) - 12.6. ISO-8601 refresh / TTL durations
- 12.1. robots.txt group selection (token
- 13. Conformance fixtures
- 14. Attestation
- 15. Conformance checklist
- 16. Self-test canaries (dogfood)
- 17. Opt-out workflow (operator side)
- 18. Build recipe
- 19. Deferred (out of scope for v1.2)
- 20. Porting notes
- 21. References
- 22. Changelog
1. Status
- Spec version:
walsh-research-compliance/v1.3(2026-05-24). Supersedes v1.2. - Bot identity governed:
Walsh-Research/MAJOR.MINOR(currently1.2). - Applies to: every tool that fetches third-party resources under the
Walsh-Researchidentity — crawlers, agents, one-off scripts — in any language. - Reference implementations: the Clojure crawler
jwalsh/tech-crawlerand a Python conformance harness (see 15.1). References, not the contract; this document is the contract. - Authoritative public surface: https://wal.sh/bot/ and the
/.well-known/walsh-research/documents (5).
This is the single, authoritative specification for the Walsh-Research bot
contract. It is written to be build-complete: a competent implementer (human
or LLM) given only this document — and the URLs it names — can produce a
conformant Walsh-Research/x.y tool in any language, then verify it against the
12 and the live 13. It specifies
behavior and data contracts, never a particular implementation.
A note on what "conformant" means: the conformant entity is the tool a publisher
runs under the Walsh-Research/1.2 identity, bound to this contract. A
general-purpose LLM that fetches a URL while reasoning is not a Walsh-Research
bot, and generating code that could be such a tool does not make the generator
one. Conformance is a property of the bound, deployed tool.
1.1. Interactive REPL use
A human driving a Walsh-Research implementation interactively at a REPL is not
an automated crawler. RFC 9309 governs automated access; a person typing
(http-get "https://example.com") and reading the output is interactive research,
not bot activity. The UA string identifies the tool lineage, not the automation
level.
Interactive REPL sessions that use the Walsh-Research UA:
- Are not bound by R4 (throttle) or R5 (backoff) — human typing speed is the natural rate limiter.
- SHOULD still honor R2 (robots.txt) and R3 (blocklist) as a matter of operational courtesy, but a human researcher exercising a single URL at a prompt is not the scenario these gates were designed to protect against.
- SHOULD tag requests with R13, using
sha=devorsha=replto distinguish interactive exploration from automated runs. - MUST use the same
Walsh-ResearchUA (R1) so the operator can identify the tool family in access logs.
The distinction: an automated gmake crawl is a bot. A human at ghci> or
user> or >>> is a researcher using the same code.
If this spec and https://wal.sh/bot/ ever disagree, https://wal.sh/bot/ is authoritative for what we promise the public; this spec is authoritative for how a conformant tool must behave.
2. How to use this document
- Read 3, 4, and the 6 table.
- Implement the 7 pipeline and requirements R1–R12. Each states its inputs, outputs, ordering, edge cases, and exact constants — everything needed to implement it with no further reference.
- Verify against the 12 (offline
input -> expectedpairs) and the live 13 (URLs you can fetch). - Self-audit with the 15; optionally emit an 14 document.
- Follow the 18 for a suggested order of work.
A note on the code. Any code in this document is Clojure, shown for demonstration only (Clojure is the reference implementation's language). It is illustrative, not prescriptive: conformance is defined by the behavior, contracts, constants, and 12 here, never by these snippets. The compliance implementation team chooses its own language and design; the 20 map the handful of primitives across languages.
3. Conformance language
The key words MUST, MUST NOT, SHOULD, SHOULD NOT, and MAY are used as in RFC 2119 / RFC 8174. A tool is conformant with a spec version when it satisfies every MUST and MUST NOT of that version. SHOULD-level items are expected; their absence must be deliberate and justifiable.
"A tool" means the software acting under the Walsh-Research identity. "A host" means a registered domain name plus optional port. "A target" means a single URL the tool has been explicitly configured to fetch.
4. Versioning and identity
Three independently-versioned contracts:
- Bot product version —
Walsh-Research/MAJOR.MINOR, carried in the User-Agent (R1). It identifies the deployed bot line, not the spec version. robots.txt matching uses only the bare product tokenWalsh-Research(R2), never the version. - Spec version —
walsh-research-compliance/vN[.M]. A breaking change to a MUST bumps the major; additive MUSTs / promoted SHOULDs bump the minor. - Data contracts —
walsh-research-blocklist/vN,walsh-research-test-fixtures/vN,walsh-research-attestation/vN, each versioned on its own.
A conformant tool MUST be able to state which spec version it targets (e.g. in
its 14). A tool targeting an older spec version remains conformant
against that version. The product version and the spec version move
independently: a tool may bump its product version (Walsh-Research/1.2) or its
targeted spec revision without the two being locked together, and a future
Walsh-Research/1.4 could still target walsh-research-compliance/v1.3.
A tool MAY additionally annotate the spec version it targets out of band in
its attestation document. A tool MAY NOT alter the exact R1 User-Agent to carry
it (R1 is an exact-match MUST); any extra UA comment token MUST NOT affect the
Walsh-Research robots token used for matching.
5. Canonical resources
A tool MUST treat these URLs as the live source of truth (no bundled copy may override a successfully fetched live document):
| Resource | URL |
|---|---|
| Public policy | https://wal.sh/bot/ |
| This spec | https://wal.sh/research/bots/compliance-spec |
| Blocklist data | https://wal.sh/.well-known/walsh-research/blocklist.json |
| Blocklist schema | https://wal.sh/.well-known/walsh-research/blocklist.schema.json |
| Test fixtures | https://wal.sh/.well-known/walsh-research/test-fixtures.json |
The blocklist document is self-describing: it carries its own JSON Schema inline
under a top-level schema key (R3c), so a tool can fetch one URL and validate it
without a second request. The standalone blocklist.schema.json remains the
canonical copy (for external tooling and as the schema's $id) and is identical.
From https://wal.sh/bot/ alone a tool can discover this spec; from the spec, the
blocklist (schema included) and fixtures; from the fixtures, every URL needed to
self-verify. The whole bootstrap is reachable from one starting URL.
The blocklist and fixtures contracts and the schema are published under no restrictions and may be reused by other operators.
6. Normative constants
These are the only tunables. Values are defaults a tool SHOULD use unless a
fetched document dictates otherwise (e.g. refresh, Crawl-delay, Retry-After).
| Constant | Value | Requirement |
|---|---|---|
USER_AGENT |
Mozilla/5.0 (compatible; Walsh-Research/1.2; +https://wal.sh/bot/) |
R1 (exact) |
UA_TOKEN |
Walsh-Research (matched case-insensitively) |
R1, R2 |
ROBOTS_TTL_SECONDS |
86400 (24h) |
R2 |
BLOCKLIST_REFRESH |
document refresh field; default PT6H (21600 s) |
R3 |
SCHEMA_TTL_SECONDS |
604800 (7d) |
R10 |
MIN_REQUEST_INTERVAL |
1.0 s per host |
R4 |
DEFAULT_MAX_RETRIES |
5 |
R5 |
DEFAULT_BACKOFF_BASE |
1.0 s (exponential) |
R5 |
BACKOFF_CAP |
60 s |
R5 |
STALE_HARD_CUTOFF |
2 × the relevant TTL (only if stale-while-revalidate is used) |
R12 |
7. Pre-request gate
For every target URL, a tool MUST evaluate the gates below in this exact order. The first gate that returns DENY stops the request; no later gate or fetch runs. The order is normative and non-commutative: R3 precedes R2 because an operator opt-out is absolute and may apply to a host whose robots.txt is itself unreachable; R4 follows both because pacing a request we will deny wastes wall clock.
// Walsh-Research pre-request gate: blocklist -> robots.txt -> throttle -> fetch digraph pre_request_gate { rankdir=TB; bgcolor=white; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10]; edge [color="#888888", fontcolor="#555555", fontname="Helvetica", fontsize=9]; url [label="Target URL", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; // Gate 1: Operator blocklist (R3) subgraph cluster_r3 { label="R3: Operator Blocklist"; style="rounded"; color="#b91c1c"; fontcolor="#b91c1c"; fontname="Helvetica"; fontsize=11; blocklist [label="Fetch blocklist.json\n(cached, PT6H refresh)", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; bl_check [label="Domain in\nblocked[]?", shape=diamond, fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; } // Gate 2: robots.txt (R2) subgraph cluster_r2 { label="R2: robots.txt (RFC 9309)"; style="rounded"; color="#6b21a8"; fontcolor="#6b21a8"; fontname="Helvetica"; fontsize=11; robots [label="Fetch /robots.txt\n(cached, 24h TTL)", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; group [label="Select group:\nWalsh-Research > *", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; disallow [label="Path\ndisallowed?", shape=diamond, fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; } // Gate 3: Rate limit (R4) subgraph cluster_r4 { label="R4: Rate Limit"; style="rounded"; color="#b45309"; fontcolor="#b45309"; fontname="Helvetica"; fontsize=11; throttle [label="Throttle\nmax(1s, Crawl-delay)", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; } // Outcomes fetch [label="FETCH\n(with backoff R5)", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; deny [label="DENY\n(skip URL)", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; // Flow url -> blocklist; blocklist -> bl_check; bl_check -> deny [label="yes", color="#b91c1c", fontcolor="#b91c1c"]; bl_check -> robots [label="no"]; robots -> group; group -> disallow; disallow -> deny [label="yes", color="#b91c1c", fontcolor="#b91c1c"]; disallow -> throttle [label="no"]; throttle -> fetch; }
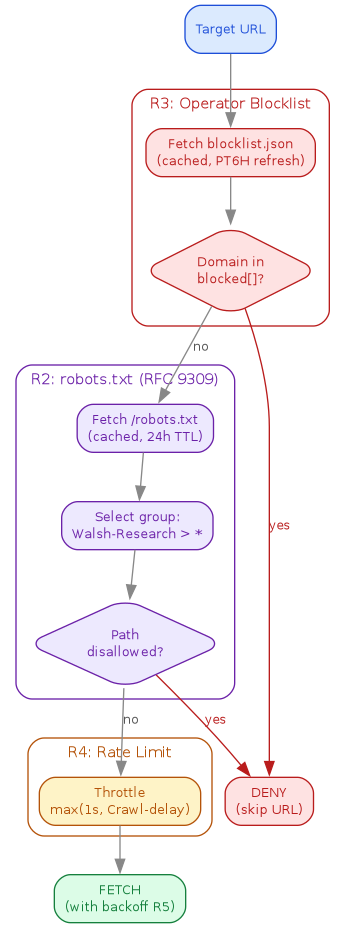
;; Demo (Clojure). The gate order is normative; the language is not. (defn may-fetch? [url] (cond (operator-blocklist-blocks? url) :deny ; R3, checked FIRST (not (robots-allows? url)) :deny ; R2, RFC 9309 :else (do (throttle! url) ; R4, blocks until the slot is free :allow)))
If may_fetch returns ALLOW the tool issues the request with conditional headers
(R7) and applies backoff (R5) to rate-limit responses.
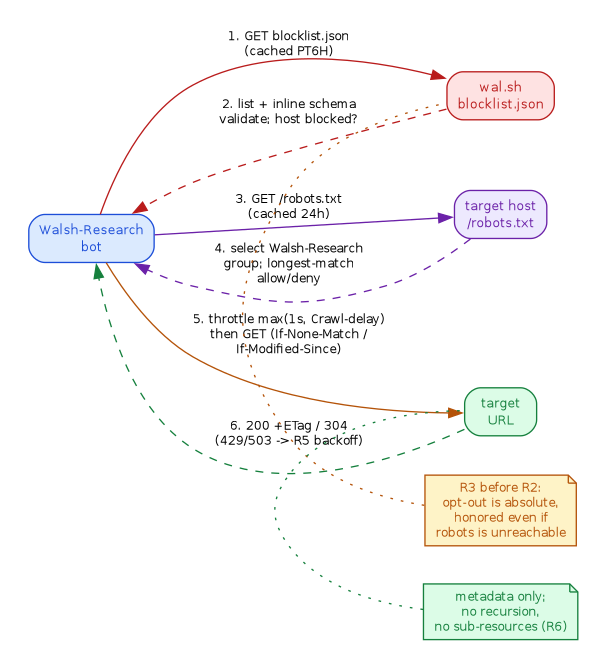
The same lifecycle as a sequence over time — one target URL, the gates in order, and the participants each step talks to:
// Walsh-Research request lifecycle sequence (R3 -> R2 -> R4 -> fetch -> R5/R7) digraph request_sequence { rankdir=LR; graph [bgcolor="white", fontname="Helvetica", fontsize=11, pad="0.3", nodesep="0.4", ranksep="0.8"]; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10]; edge [fontname="Helvetica", fontsize=9, color="#888888"]; bot [label="Walsh-Research\nbot", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; blocklist [label="wal.sh\nblocklist.json", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; robots [label="target host\n/robots.txt", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; target [label="target\nURL", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; // R3: operator blocklist, checked first bot -> blocklist [label="1. GET blocklist.json\n(cached PT6H)", color="#b91c1c"]; blocklist -> bot [label="2. list + inline schema\nvalidate; host blocked?", style=dashed, color="#b91c1c"]; // R2: robots.txt (RFC 9309) bot -> robots [label="3. GET /robots.txt\n(cached 24h)", color="#6b21a8"]; robots -> bot [label="4. select Walsh-Research\ngroup; longest-match\nallow/deny", style=dashed, color="#6b21a8"]; // R4 throttle, conditional fetch (R7), backoff (R5) bot -> target [label="5. throttle max(1s, Crawl-delay)\nthen GET (If-None-Match /\nIf-Modified-Since)", color="#b45309"]; target -> bot [label="6. 200 +ETag / 304\n(429/503 -> R5 backoff)", style=dashed, color="#15803d"]; note1 [label="R3 before R2:\nopt-out is absolute,\nhonored even if\nrobots is unreachable", shape=note, fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309", fontsize=9, style="filled"]; note2 [label="metadata only;\nno recursion,\nno sub-resources (R6)", shape=note, fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d", fontsize=9, style="filled"]; { rank=same; blocklist; note1; } { rank=same; target; note2; } note1 -> blocklist [style=dotted, color="#b45309", arrowhead=none, constraint=false]; note2 -> target [style=dotted, color="#15803d", arrowhead=none, constraint=false]; }
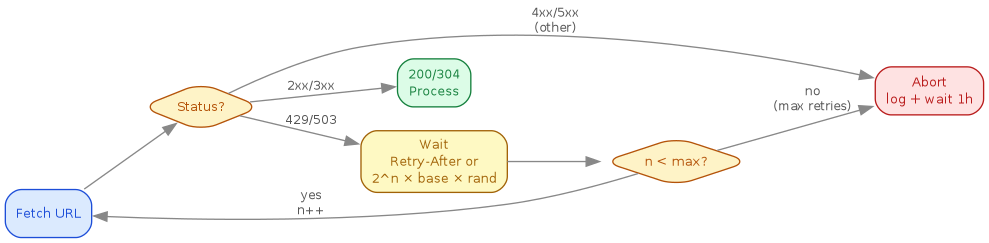
// Walsh-Research backoff state machine (R5): retry on 429/503 digraph backoff_states { rankdir=LR; bgcolor=white; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10]; edge [color="#888888", fontcolor="#555555", fontname="Helvetica", fontsize=9]; fetch [label="Fetch URL", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; check [label="Status?", shape=diamond, fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; success [label="200/304\nProcess", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; wait [label="Wait\nRetry-After or\n2^n x base x rand", fillcolor="#fef9c3", color="#a16207", fontcolor="#a16207"]; retry_check [label="n < max?", shape=diamond, fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; abort [label="Abort\nlog + wait 1h", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; fetch -> check; check -> success [label="2xx/3xx"]; check -> wait [label="429/503"]; check -> abort [label="4xx/5xx\n(other)"]; wait -> retry_check; retry_check -> fetch [label="yes\nn++"]; retry_check -> abort [label="no\n(max retries)"]; }
8. Identity — R1
8.1. R1 — User-Agent (MUST)
Every request MUST carry the exact USER_AGENT header value from
6.
- The product token for robots.txt matching is
Walsh-Research, matched case-insensitively (R2). - The token MUST be followed by a
MAJOR.MINORproduct version, so the declared identity isWalsh-Research/<major>.<minor>(currentlyWalsh-Research/1.2). The version is part of the exact UA string but is not used for robots matching (R2 keys on the bareWalsh-Researchtoken); it lets operators read the bot's product line from their access logs and lets the product version move independently of the spec version (4). - The
+URL MUST resolve to a public policy page describing the bot and how to opt out. - A tool MUST NOT impersonate a browser or another crawler, or omit the token, or rotate/randomize the User-Agent to evade rules.
9. Pre-request gates — R2, R3, R4, R5
9.1. R2 — robots.txt, RFC 9309 (MUST)
A tool MUST fetch /robots.txt over the target's scheme+host, parse it per RFC
9309, and obey the rules selected for the Walsh-Research token before fetching
any target on that host. It SHOULD cache robots.txt per host for
ROBOTS_TTL_SECONDS.
9.1.1. Fetch and error handling
- Fetch
SCHEME://HOST[:PORT]/robots.txt. 200-> parse the body.4xx(including404) -> treat as no rules: everything allowed.5xx, network error, or timeout -> a tool SHOULD fail open (allow) but MAY defer the host; it MUST NOT treat an unreachable robots.txt as a blanket disallow that silently drops a host forever.- A body over 500 KiB MAY be truncated to 500 KiB before parsing.
9.1.2. Group parsing
A group is one or more consecutive User-agent lines followed by the rule
lines (Allow, Disallow, Crawl-delay) that apply to them. A User-agent line
appearing after a rule line starts a new group. Lines are field: value; #
begins a comment; field names are case-insensitive; surrounding whitespace is
trimmed; blank lines are ignored. Records with the same User-agent value merge.
9.1.3. Group selection (RFC 9309 §2.2.1, longest match)
Let T = "walsh-research" (lowercased token).
For each User-agent value U (lowercased), U matches T when any of:
U = "*"(wildcard)U = T(exact match)Uis a prefix ofT(walshmatcheswalsh-research)
Selection precedence:
- The non-
*group whose matchingUis longest wins. - If no named group matches, use the
*group. - If no
*group exists, no rules apply (allow all).
A named group therefore overrides * in both directions: it can disallow
where * allows, and allow where * disallows. Only the selected group's
rules are consulted.
A tool that wraps a parser lacking longest-match selection MUST add a selection layer.
\* Group selection algorithm (RFC 9309 §2.2.1) SelectGroup(groups, T) == LET matches == {g \in groups : LET U == Lowercase(g.user_agent) IN U = T \/ IsPrefix(U, T)} best == CHOOSE g \in matches : \A h \in matches : Len(g.user_agent) >= Len(h.user_agent) IN IF matches /= {} THEN best ELSE IF \E g \in groups : g.user_agent = "*" THEN CHOOSE g \in groups : g.user_agent = "*" ELSE NoRules
9.1.4. Path matching within the selected group (RFC 9309 §2.2.2–2.2.3)
Match the request's path + query (default / when empty) against the group's
Allow and Disallow rules:
- A rule value
""matches nothing (an emptyDisallowallows all). *matches any sequence (including none);$anchors to the end of path+query.- Otherwise a rule matches if path+query starts with the rule value (after
expanding any
*). - Compare percent-encoding consistently (decode unreserved octets on both sides).
Decision: among matching rules, the longest value wins (an expanded * counts
as the characters it consumed). On a length tie, Allow wins. A winning
Disallow -> denied; a winning Allow, or no match -> allowed.
A tool that does not implement Allow or *=/=$ MAY degrade only in the safe
direction: it MUST NOT fetch a URL the full algorithm would deny
(no under-blocking), but it MAY over-block a URL an Allow would have
permitted. Under-blocking is a violation; conservative over-blocking is not.
9.1.5. Crawl-delay (de-facto extension, MUST honor)
Crawl-delay is not in RFC 9309 but is widely deployed; a tool MUST honor it
when present in the selected group as the minimum seconds between requests to that
host (R4). Fractional allowed; ignore a non-numeric value.
9.1.6. Opt-out a site can self-serve
User-agent: Walsh-Research Disallow: /
9.2. R3 — Operator blocklist (MUST)
Some opt-outs arrive out of band (email to j@wal.sh). They live in one published JSON document that every Walsh-Research tool MUST consult, so an opt-out is honored uniformly across tools and languages. It is checked before robots.txt and is in addition to it.
Contract walsh-research-blocklist/v1:
{
"$schema": "https://wal.sh/.well-known/walsh-research/blocklist.schema.json",
"contract": "walsh-research-blocklist/v1",
"updated": "2026-05-23T00:00:00Z",
"operator": "Jason Walsh",
"contact": "j@wal.sh",
"policy": "https://wal.sh/bot/",
"refresh": "PT6H",
"blocked": [
{ "domain": "example.com", "added": "2026-05-23", "reason": "email opt-out" }
]
}
The schema value above is abbreviated; in the live document it is the complete
Draft 2020-12 schema, byte-identical to the standalone blocklist.schema.json.
| Field | Type | Meaning |
|---|---|---|
contract |
string | walsh-research-blocklist/vN; reject an unknown major |
updated |
string | RFC 3339 timestamp the list last changed |
refresh |
string | ISO-8601 duration; cache TTL (PT6H = 6h) |
schema |
object | inline Draft 2020-12 schema; validate the document against it (R3c) |
blocked[] |
array | opt-out entries |
blocked[].domain |
string | registered domain (apex) to block |
blocked[].added |
string | date added (informational) |
blocked[].reason |
string | reason (informational) |
Requirements:
- A tool MUST skip any request whose host equals a listed
domainor is a subdomain of it. Match case-insensitively with port stripped: hostHis blocked by domainDiffH = DorHends with"." + D. (example.comblocksexample.com,www.example.com; notnotexample.comorexample.com.evil.test.) - (R3c, MUST) A tool MUST validate the document before adopting it, and
MUST NOT adopt one that fails validation or whose
contractmajor is unknown — retain the previously held list instead. The document is self-describing: a tool SHOULD validate against the inlineschemafield (single fetch); if it is absent, fall back to the standaloneblocklist.schema.json(R10). Validating a document against its own embedded schema is a structural check (it catches malformed or wrong-contract data), not anti-tamper; transport integrity (HTTPS to the canonical origin) covers tampering. - A tool SHOULD cache the list for the
refreshduration. Timing is dictated by the data, not hard-coded. - (R3b, MUST) On fetch failure, timeout, or
404, retain the last-known list: a transient outage MUST NOT silently un-block an opt-out. The first-ever fetch failing yields an empty list (fail open) — nothing is protected yet.
9.3. R4 — Rate limiting and Crawl-delay (MUST)
- Requests MUST be serial within a process: no concurrent connections.
- A tool MUST NOT exceed one request per second per host.
- Minimum spacing before the next request to a host is
max(MIN_REQUEST_INTERVAL, Crawl-delay)(R2). - The first request to a previously-unseen host MUST NOT be delayed.
- The throttle key is the host.
;; Demo (Clojure). Blocks the caller until the host's slot is free. (defn throttle! [url] (let [host (host-of url) interval (max min-request-interval (robots-crawl-delay host)) last (get @last-request-time host)] ; nil => unseen => no wait (when last (let [wait (- (+ last interval) (now))] (when (pos? wait) (sleep wait)))) (swap! last-request-time assoc host (now))))
(R4a, informational.) "Serial within a process" means a deployment that runs multiple instances MUST add cross-process coordination (a file lock, shared store, or token bucket) to keep the per-host ceiling. Single-instance scheduling is the recommended default.
9.4. R5 — Backoff and Retry-After (MUST)
On HTTP 429 or 503 a tool MUST back off and retry. Other 5xx MAY be
retried with the same policy.
- If
Retry-Afteris present, wait at least that long, using it in place of the computed delay.Retry-Afteris either integer seconds or an HTTP-date (RFC 9110); for the date form compute the delay to that instant (clamp negatives to 0). - Otherwise use exponential backoff with full jitter:
delay = random_between(0, min(BACKOFF_CAP, DEFAULT_BACKOFF_BASE * 2^attempt)),attemptstarting at 0. - A tool MUST bound retries at
DEFAULT_MAX_RETRIES, then give up for that target and record the failure. - A tool MUST NOT retry faster than the schedule, and MUST NOT treat a
429=/=503as success.
10. Scope and data-handling limits — R6, R7, R8, R9
10.1. R6 — Stay in scope (MUST / MUST NOT)
- MUST NOT follow links or crawl recursively; fetch only declared targets.
- MUST NOT download sub-resources (images, scripts, stylesheets, fonts).
- MUST NOT train models on, index for search, or republish fetched content. Extract metadata, not content.
- MUST NOT retain fetched content beyond what the immediate analysis needs.
10.2. R7 — Cache-friendly and de-duplicating (SHOULD)
Conditional requests. Store the ETag response header and replay it as
If-None-Match; store Last-Modified and replay as If-Modified-Since. On 304
Not Modified: treat as "no new data", do no further processing, keep the stored
validators. On 200: process and refresh the validators.
Canonical-URL de-duplication. Dedup results by a canonical key:
- Lowercase scheme and host.
- Drop a default port (
80http,443https). - Remove the fragment (from
#). - Empty path ->
/; else strip a single trailing/(never reduce/to empty). - Preserve the query string verbatim (do not reorder or drop parameters).
Canonical string: scheme://host[:non-default-port]path[?query].
10.3. R8 — Frequency (SHOULD)
A tool SHOULD fetch each source infrequently — daily or less — and
SHOULD NOT re-fetch a source more than once per hour absent a specific reason.
Enforcement is an orchestration concern (a per-source last_run_at), not gate
logic.
10.4. R9 — Prefer structured formats; never scrape HTML (SHOULD / MUST NOT)
A tool MUST NOT extract content by scraping arbitrary HTML with per-site CSS or XPath selectors.
Markdown-first by content negotiation (general rule). Whenever a tool would
request a page that it expects to be HTML, it SHOULD first send
Accept: text/markdown and use the response body when the server answers with a
markdown content-type (the Content-Type contains markdown), falling back to
HTML (or another representation) only when markdown is not offered. This is one
extra request header and yields a clean, selector-free representation, so it is
the default for any page fetch, not only feed-less sources. A growing set of
docs platforms content-negotiate markdown; most sites ignore the header and
return HTML, which is fine.
For a feed-less source a tool SHOULD obtain a structured representation, preferring, in order:
- A real feed (RSS / Atom / JSON Feed) when one exists.
- Content negotiation — send
Accept: text/markdown; use the body only if the responseContent-Typecontainsmarkdown. - llms.txt — fetch
/llms.txtat the host root (https://llmstxt.org), often served astext/plain; accept atext/plainbody there as markdown.
From any markdown body, extract items generically: inline links [text](url)
with absolute http(s) url, de-duplicated, in document order; text is the
title. A tool MUST NOT rely on per-site structure. A source offering none of the
above is left out, not scraped. llms.txt is advisory: R2 and R3 still decide
whether a tool may fetch.
11. Caching and persistence — R10, R11, R12
11.1. R10 — Blocklist schema: inline-first, external fallback (MUST)
The blocklist is self-describing (R3c): in the common path a tool validates
against the inline schema field and performs no separate schema fetch, so the
schema shares the blocklist's refresh TTL and there is nothing extra to cache.
The rules below govern the fallback path — a document that omits schema,
where the tool fetches the standalone blocklist.schema.json:
- A tool SHOULD cache the external schema for
SCHEMA_TTL_SECONDS. - On an external-schema refresh failure with a prior schema cached, a tool SHOULD retain and use the stale schema (fail-open) and MUST log it. A transient upstream failure must not silently disable validation.
- (MUST) If a document omits
schemaand no external schema can be obtained (none inline, none cached, fetch fails), a tool MUST NOT adopt the document — with no schema at all there is no way to distinguish a valid blocklist from arbitrary JSON. Deliberately asymmetric with R3's data fail-open: "cannot validate" is fail-closed for adoption.
11.2. R11 — Persistent caches (SHOULD)
A tool SHOULD persist its robots.txt, blocklist, and schema caches across process invocations, so a tool invoked once per cron run does not re-fetch every time. Storage format and location are the implementer's choice (JSON, SQLite, EDN, language-native serialization). The contract is external — observable fetch behavior at the declared TTLs — not how the cache is stored.
11.3. R12 — Cache-miss behavior (clarification)
When a cache entry is stale, the default is block-on-refresh: the next request
stalls until the refresh completes (deterministic, no async machinery). A tool
MAY instead implement stale-while-revalidate with a hard cutoff at
STALE_HARD_CUTOFF. Either is conformant.
12. Conformance test vectors
These input -> expected pairs are normative and implementation-free; a
conformant tool MUST reproduce every expected output. They double as a portable
offline suite.
12.1. robots.txt group selection (token Walsh-Research)
| robots.txt (groups) | selected group | why |
|---|---|---|
*: Disallow /a ‖ Walsh-Research: Disallow /b |
Walsh-Research | named beats * |
*: Disallow /a |
* |
no named group |
walsh: Disallow /x ‖ walsh-research: Disallow /y |
walsh-research | longest prefix match |
Googlebot: Disallow / |
(none) | no named, no * -> allow all |
WALSH-RESEARCH: Disallow /z |
WALSH-RESEARCH | case-insensitive |
12.2. robots.txt path matching (within the selected group)
| rules | path | result | why |
|---|---|---|---|
| Disallow: /research/bots/dogfood-disallow | /research/bots/dogfood-disallow.html | DENY | prefix match |
| Disallow: /research/bots/dogfood-disallow | research/bots | ALLOW | not a prefix of the rule |
| Disallow: / | /anything | DENY | root disallow |
| Disallow: | /anything | ALLOW | empty Disallow matches nothing |
| Disallow: /a + Allow: /a/b | /a/b/c | ALLOW | longer Allow wins |
| Disallow: /a + Allow: /a | /a/x | ALLOW | equal length -> Allow wins |
| Disallow: /*.pdf$ | /docs/report.pdf | DENY | * + end-anchor |
| Disallow: /*.pdf$ | /docs/report.pdf?x=1 | ALLOW | $ anchors end; query breaks it |
12.3. Blocklist domain matching (listed domain example.com)
| host | blocked? |
|---|---|
| example.com | yes |
| www.example.com | yes |
| a.b.example.com | yes |
| EXAMPLE.COM | yes |
| notexample.com | no |
| example.com.evil.test | no |
| example.org | no |
12.4. URL canonicalization (for dedup)
| input | canonical |
|---|---|
HTTP://Example.com/Path/ |
http://example.com/Path |
https://x.test:443/a#frag |
https://x.test/a |
http://x.test:80/ |
http://x.test/ |
https://x.test |
https://x.test/ |
https://x.test/a/?q=1#f |
https://x.test/a?q=1 |
https://x.test/a?b=2&a=1 |
https://x.test/a?b=2&a=1 |
12.5. Retry-After parsing (now = Mon, 23 May 2026 00:00:00 GMT)
| Retry-After | delay |
|---|---|
120 |
120 s |
0 |
0 s |
Mon, 23 May 2026 00:00:30 GMT |
30 s |
Mon, 23 May 2026 00:00:00 GMT |
0 s |
Sun, 23 May 2026 00:00:00 GMT (past) |
0 s |
12.6. ISO-8601 refresh / TTL durations
| duration | ms |
|---|---|
PT6H |
21600000 |
PT30M |
1800000 |
P1D |
86400000 |
PT1H30M |
5400000 |
13. Conformance fixtures
Live URLs a tool can fetch to self-verify the gates end-to-end. They are
enumerated machine-readably in test-fixtures.json (contract
walsh-research-test-fixtures/v1):
{
"contract": "walsh-research-test-fixtures/v1",
"updated": "2026-05-23T00:00:00Z",
"fixtures": {
"robots_allowed_sentinel": "https://wal.sh/research/bots/dogfood-allow",
"robots_disallowed": "https://wal.sh/research/bots/dogfood-disallow",
"walsh_only_allowed": "https://wal.sh/research/bots/dogfood-walsh-only",
"external_positive": "https://pypi.org/project/jsonschema/",
"operator_blocked_host": "example.com",
"flaky_429_endpoint": null
},
"notes": {
"external_positive": "PyPI project page (robots-allowed). Do NOT use /pypi/<name>/json: pypi.org Disallows /pypi/*/json, so a robots-respecting bot must refuse it.",
"flaky_429_endpoint": "no live R5 fixture; tools SHOULD use a local mock"
}
}
| Fixture | Expected for Walsh-Research |
|---|---|
robots_allowed_sentinel |
fetched (200); allowed by robots |
robots_disallowed |
refused at R2, every representation (.html, .md, none) |
walsh_only_allowed |
fetched; * bots are Disallow-ed here, our named group is not |
external_positive |
fetched (200); a robots-allowed third-party page, sandbox-reachable |
operator_blocked_host |
any URL on this host refused at R3 (live blocklist entry) |
Verify these live (same site): the fixtures index test-fixtures.json, the canaries dogfood-allow / dogfood-disallow / dogfood-walsh-only, the self-describing blocklist.json and its blocklist.schema.json, and robots.txt.
The external positive is pypi.org/project/jsonschema/ because PyPI is reachable
from inside the sandboxes LLM harnesses run in (the package index is allowlisted
almost universally); a self-test target must work there or the spec cannot be
self-verified from a single-prompt bootstrap. Note the correction: the obvious
pypi.org/pypi/<name>/json API path is robots-disallowed (Disallow:
/pypi/*/json), so a conformant bot must refuse it – the project page is the
correct allowed positive. No live 429 fixture is provided — R5 is verified
against a local mock.
14. Attestation
A tool MAY publish a self-attestation so publishers and auditors can compare implementations. It is not consulted by any gate — robots.txt and the blocklist already decide routing — it is ecosystem hygiene only.
Contract walsh-research-attestation/v1:
{
"contract": "walsh-research-attestation/v1",
"tool": "<implementer-chosen name>",
"tool_version": "<semver or freeform>",
"spec": "walsh-research-compliance/v1.3",
"user_agent": "Mozilla/5.0 (compatible; Walsh-Research/1.2; +https://wal.sh/bot/)",
"requirements": { "R1": true, "R2": true, "R3": true, "...": true }
}
The publishing location is the implementer's choice (a URL on the operator's site, a release artifact). The spec defines the document shape, not where it lives. Signing (e.g. Ed25519 over the JSON canonical form, keys at a published JWKS) is a future option, deferred until a consumer needs it.
15. Conformance checklist
A tool is conformant when every MUST holds.
| # | Requirement | Level |
|---|---|---|
| R1 | exact User-Agent; token case-insensitive; no impersonation | MUST |
| R2 | robots.txt fetched, cached (ROBOTS_TTL_SECONDS), obeyed; RFC 9309 |
MUST |
| R2a | named Walsh-Research group overrides *, longest-match selection |
MUST |
| R2b | path: longest-match, Allow wins ties, *=/=$ wildcards |
MUST |
| R2c | may over-block (skip Allow/wildcards), MUST NOT under-block | MUST |
| R2d | Crawl-delay honored | MUST |
| R3 | operator blocklist consulted before robots | MUST |
| R3a | apex + subdomain match, case-insensitive, port-stripped | MUST |
| R3b | retain last list on fetch failure / 404 | MUST |
| R3c | validate against schema; reject invalid / unknown contract major | MUST |
| R4 | serial; <= 1 req/s/host; spacing = max(1s, Crawl-delay); unseen no wait | MUST |
| R5 | 429/503 backoff + full jitter; cap; <= 5 retries; Retry-After | MUST |
| R6 | no recursion / sub-resources / training / republish; metadata-only | MUST |
| R7 | conditional fetch (ETag / Last-Modified) + canonical-URL dedup | SHOULD |
| R8 | infrequent (daily or less) | SHOULD |
| R9 | feed > content-neg markdown > llms.txt; never scrape HTML | SHOULD/MUST NOT |
| R10 | schema TTL; stale-on-failure; first-fetch-fail MUST NOT adopt | MUST |
| R11 | persist caches across invocations (format = implementer's choice) | SHOULD |
| R12 | cache-miss: block-on-refresh default (SWR with 2×TTL cutoff allowed) | clarification |
15.1. Reference-implementation notes
Two complementary references, neither the contract:
jwalsh/tech-crawler(Clojure): satisfies every MUST except R2b — its path matcher is a conservative subset (honorsDisallowprefixes and correct longest-match group selection; treatsAllowand*=/=$as no-ops), so it may over-block (permitted by R2c). Group-token longest-match selection is correct.- Python conformance harness: full RFC 9309 path matching (Allow + wildcards)
via the platform robots parser, but first-match group selection rather than
longest-match (R2a), so it adds a selection layer. Verified 21/21 against a
localhost mock plus a live smoke test. Archived in
aygp-dr/walsh-research-compliance/archive/.
Together they cover both halves of R2; a fully-conformant tool does both.
16. Self-test canaries (dogfood)
We hold our own tools to this spec against the live site. Three sibling pages
under /research/bots/ exercise the R2 gate in all directions at one path depth:
| Canary | * sees |
Walsh-Research sees | Bot must |
|---|---|---|---|
| dogfood-disallow | allowed | Disallow |
refuse |
| dogfood-allow | allowed | allowed | fetch |
| dogfood-walsh-only | Disallow |
Allow (named) |
fetch |
User-agent: * Disallow: /research/bots/dogfood-walsh-only User-agent: Walsh-Research Disallow: /research/bots/dogfood-disallow Allow: /research/bots/dogfood-allow Allow: /research/bots/dogfood-walsh-only Crawl-delay: 2
dogfood-disallowproves we honorDisallowacross every content-negotiated representation (.html,.md, extensionless): the decision is made from the path before any fetch.dogfood-allowproves we do not over-block an allowed sibling.dogfood-walsh-onlyproves the other direction of R2a: a generic*bot is disallowed, but our named group selects past*and is permitted, so we fetch. It doubles as a honeypot: since*is disallowed, the only legitimate fetchers are humans (browsers ignore robots.txt) andWalsh-Research, so any other agent in the access logs is a robots-violating bot.
These pages are intentionally undocumented elsewhere — they exist only to be
crawled or refused by a conformance run. A conformant tool SHOULD assert all
three outcomes against the live robots.txt as an attestation.
17. Opt-out workflow (operator side)
- A site self-serves via robots.txt (R2) at any time — honored within the robots cache TTL.
- Or emails j@wal.sh; the operator appends a
{domain, added, reason}entry toblocklist.jsonand deploys — honored within therefreshTTL.
A tool implementer's only job is to consume both sources correctly.
18. Build recipe
A suggested order to build a Walsh-Research/x.y tool from this document alone:
- Primitives. HTTP client, XML+JSON parser, monotonic clock + sleep, SHA-256. (20 maps these per language.)
- R1. Hard-code
USER_AGENT; send it on every request. - R2 parser. Groups -> selection -> path matching; pass the robots
12; cache per host (
ROBOTS_TTL_SECONDS). - R3 + R10. Fetch schema (cache
SCHEMA_TTL_SECONDS, stale-on-failure), validate the blocklist, cache it (refresh), domain matching, retain-on-failure; pass the blocklist vectors. - Gate. Wire
may_fetchin the normative order: blocklist -> robots -> throttle. - R4 + R5. Throttle and backoff; pass the Retry-After / duration vectors.
- R7 + R11. Conditional headers, canonical-URL dedup, persistent caches.
- R9. Feeds; markdown content negotiation and
/llms.txtfallbacks; generic link extraction. Never per-site selectors. - Attest. Run against the live 13 and the 16; emit an 14 recording the spec version targeted.
A tool that reproduces every 12 block, passes the live
fixtures and all three dogfood canaries, with the gate in the normative order, is
conformant with walsh-research-compliance/v1.3.
19. Deferred (out of scope for v1.2)
- Content-Signal (
draft-romm-aipref-contentsignals;ai-train,search,ai-input, advertised inwal.sh/robots.txt) is orthogonal to the four primitives and binds only a pipeline that performs the named use. The current bot is a metadata extractor that does not feed an LLM, soai-inputis not binding. A future bot version that adds LLM summarization would makeai-inputbinding on its intake; defining which pipeline operations count is a v2 item. - Attestation signing and a keys endpoint — deferred until a consumer needs verifiable attestations.
- Cross-process throttle backend (Redis / SQLite token bucket) — deferred; single-instance scheduling is the v1.2 default (R4a).
19.1. Redirect policy (C6)
3xx handling is undefined. Following a redirect can leave robots scope
(/research/aoc/src redirects to /research/aoc/src/ which may have
different robots rules). Proposed for v1.4: re-run the Location header
value through the full gate pipeline (R3→R2→R4) before fetching the
redirected URL. Current behavior (transparent redirect via the HTTP
library) is acceptable for v1.2/v1.3 but should be tightened.
Cross-runtime redirect limits vary from 7 (Perl LWP) to 50 (curl) – see HTTP Redirect Limits: One Ouroboros, Six Languages for empirical measurements. The six-language crawler inherits each library's default, which means a chain of 8 hops works for Python but fails for Perl. Normalizing the limit is part of the v1.4 scope.
- Transport error retry (C5) — R5 covers 429/503 but is silent on connection/TLS/timeout failures. Proposed for v1.4: apply the same backoff policy to transport errors. Surfaced by 6+ implementations in the compliance harness.
- R13×R2 interaction (C1) — R13 appends query parameters; R2 path matching includes query. Resolution adopted by all 29 implementations: gates evaluate the untagged URL; R13 params are appended only at HTTP transmission. Proposed for v1.4: codify this as normative.
20. Porting notes
Nothing here depends on a language. Each requirement is behavior over four primitives every language has; only the primitives change.
| Primitive | Clojure | Python | Rust | Guile | TypeScript | Go |
|---|---|---|---|---|---|---|
| HTTP client | clj-http | httpx / requests | reqwest | web client | fetch / undici | net/http |
| XML parse | clojure.data.xml | xml.etree | quick-xml | sxml | fast-xml-parser | encoding/xml |
| JSON parse | cheshire | json | serde_json | guile-json | JSON.parse | encoding/json |
| Clock+sleep | currentTimeMillis/sleep | time / sleep | std::time | usleep | Date.now/setTimeout | time |
| SHA-256 | MessageDigest | hashlib | sha2 | gcrypt | crypto.subtle | crypto/sha256 |
21. References
- RFC 9309 — Robots Exclusion Protocol (robots.txt).
- RFC 8615 — Well-Known URIs (
/.well-known/). - RFC 9110 — HTTP Semantics (User-Agent §10.1.5; Retry-After §10.2.3).
- RFC 2119 / RFC 8174 — requirement keywords.
draft-romm-aipref-contentsignals/ contentsignals.org — Content-Signal.- llmstxt.org — the llms.txt convention (Howard, 2024).
22. Changelog
- v1 (2026-05-23) — initial: R1 UA, R2 robots/RFC 9309 + Crawl-delay, R3 blocklist + schema, R4 rate limit, R5 backoff, R6 scope, R7 conditional fetch + dedup, R8 frequency; rev 2 added R9 (structured formats); rev 3 added the dogfood canary pair.
- v1.1 (2026-05-23) — make the spec a standalone, single-prompt-bootstrappable
build target. Folds in v1 rev 1–3. Tightens R2 to full RFC 9309 path matching
(Allow precedence +
*=/=$, with a safe over-block allowance, R2b/R2c) and longest-match group selection (R2a). Promotes schema validation to MUST (R3c). Adds R10 (schema cache + stale-on-failure), R11 (persistent caches), R12 (cache-miss behavior). Pins exact algorithms for R3 domain matching, R5 Retry-After, R7 canonical URL, and durations, plus a single 6 table. Adds 12, live 13 (test-fixtures.json) with thedogfood-walsh-onlybidirectional canary and a sandbox-reachable external positive, an 14 contract, a 18, and the 4 model. Code examples are Clojure (the reference language) shown for demonstration only; conformance is defined by behavior, contracts, and test vectors, and is language-agnostic. - v1.2 (2026-05-24) — bump bot identity from
Walsh-Research/1.1toWalsh-Research/1.2; updateUSER_AGENTconstant, attestation example, and all normative references accordingly. Add R13 (implementation tagging). No other behavioral requirements changed. - v1.3 (2026-05-24) — add R13 (implementation tagging, SHOULD). Add bot
compliance lab with 19 per-bot canary pages at
/research/bots/lab/disallow-{token}/for empirical robots.txt compliance verification. Seven implementations across six languages (TypeScript, Clojure, Python, Elisp, Guile, JavaScript) updated to v1.2 bot identity and v1.3 spec references.
22.1. R13: Implementation tagging (SHOULD)
When a conformant tool runs its test suite against the live 13
or compliance-relevant URLs (robots.txt, blocklist.json, dogfood-* pages), it
SHOULD append query parameters identifying the implementation:
https://wal.sh/robots.txt?impl=walsh/research&sha=afd2c01&spec=walsh-research-compliance/v1.3
| Parameter | Value | Purpose |
|---|---|---|
impl |
{org}/{repo} |
Which implementation is running the test |
sha |
short git SHA | Which commit of that implementation |
spec |
spec version string | Which spec version the tool targets |
This enables the spec operator to cross-reference access logs against known implementations without requiring out-of-band coordination. The query parameters MUST NOT affect the semantics of the request — they are observability metadata only.
A tool MAY auto-detect its identity from GITHUB_REPOSITORY / GITHUB_SHA
environment variables (CI) or from git remote get-url origin / git rev-parse
--short HEAD (local).
This requirement is a SHOULD because it aids operator observability but is not necessary for correct protocol behavior. A tool that omits these parameters is still conformant.
(defn tag-compliance-url "Append implementation identity to compliance fixture URLs." [url {:keys [repo sha spec-version]}] (if (and repo (str/includes? url "wal.sh")) (str url (if (str/includes? url "?") "&" "?") "impl=" (java.net.URLEncoder/encode repo "UTF-8") (when sha (str "&sha=" sha)) "&spec=" (or spec-version spec-version)) url)) ;; Usage in the pre-request pipeline: (tag-compliance-url "https://wal.sh/robots.txt" {:repo "walsh/research" :sha "afd2c01" :spec-version spec-version}) ;; => "https://wal.sh/robots.txt?impl=walsh%2Fresearch&sha=afd2c01&spec=walsh-research-compliance/v1.3"