REPL-Driven Feed Crawling
Table of Contents
Thesis
The best interface between an agent and a complex system is a REPL. A feed crawler is that problem in miniature: dozens of sources, each a replica of "the ecosystem" published in a different format, on a different cadence, with different reliability. You do not learn a source's contract by reading docs — you learn it by evaluating against it and watching the shape come back. The REPL is where each evaluation informs the next hypothesis and intermediate state persists across the session.
This is the companion to REPL-Driven Flight Tracking. Same thesis, different domain. There the divergence between replicas of one airspace was the signal; here the divergence between formats is the standing maintenance burden, and the REPL is how you stay ahead of it. It is also how an agent keeps a crawler alive as feeds drift, break, and disappear underneath it.
Source landscape
// Feed source taxonomy: heterogeneous formats -> one normalized item digraph source_taxonomy { rankdir=TB; graph [bgcolor="white", fontname="Helvetica", fontsize=11, pad="0.3", nodesep="0.35", ranksep="0.55"]; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10]; edge [color="#888888", fontname="Helvetica", fontsize=9]; subgraph cluster_xml { label="XML feeds"; style="rounded"; color="#1d4ed8"; fontcolor="#1d4ed8"; fontsize=11; rss2 [label="RSS 2.0", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; rdf [label="RSS 1.0 / RDF", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; atom [label="Atom", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; } subgraph cluster_json { label="JSON"; style="rounded"; color="#15803d"; fontcolor="#15803d"; fontsize=11; jsonfeed [label="JSON Feed", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; localist [label="Localist (events)", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; } subgraph cluster_pages { label="Feed-less pages"; style="rounded"; color="#b45309"; fontcolor="#b45309"; fontsize=11; md [label="markdown /\nllms.txt", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; html [label="HTML\n(last resort)", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; } feed_a [label="feed adapter\n(namespace-agnostic;\nlocal element names)", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; json_a [label="json adapter", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; md_a [label="markdown adapter\n(generic links)", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; html_a [label="enlive adapter\n(per-site selectors)", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; item [label="normalized item\n{:title :url :source :date :tags}", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; rss2 -> feed_a; rdf -> feed_a; atom -> feed_a; jsonfeed -> json_a; localist -> json_a; md -> md_a; html -> html_a [style=dashed, label="avoid"]; feed_a -> item; json_a -> item; md_a -> item; html_a -> item [style=dashed]; }
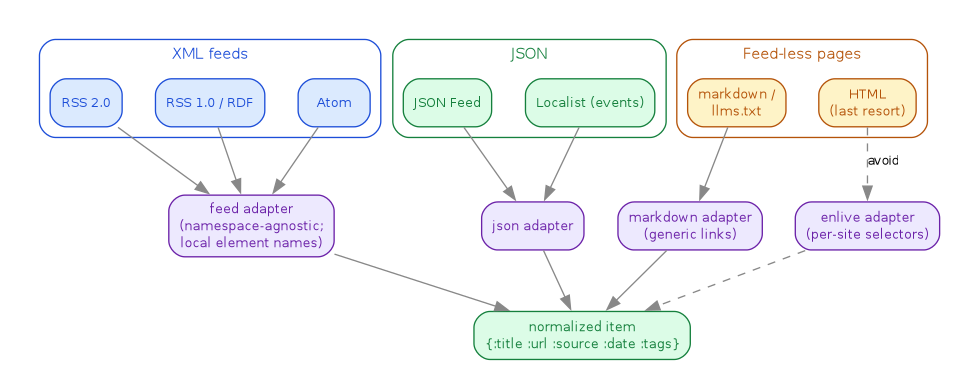
tech-crawler aggregates ~60 sources into one item shape. They share almost
nothing at the wire: RSS 2.0, RSS 1.0/RDF, and Atom disagree on element names and
namespaces; JSON Feed and Localist are different object graphs; feed-less sites
offer only HTML or, increasingly, markdown. The standing bet is conjecture
C-001: a single normalize path handles more than 80% of the variance, so the
adapters stay thin. One generic feed adapter navigates by local element name,
which makes the RSS/RDF/Atom namespace differences disappear, and HTML scraping
is the explicit last resort (it degrades into per-site selector maintenance).
Contract verification
The normalized contract is \{:title :url :source :date :tags\}. Verifying that a
source actually produces it is the crawler's analogue of the flight-tracker's
cross-source diff: you fetch, parse, and check the shape, and the places it does
not hold are the work.
The messy field is always the date. RSS gives RFC-822 (Mon, 23 May 2026
12:00:00 +0000); Atom gives RFC-3339 (2026-05-23T12:00:00Z); some feeds give
neither. The adapter normalizes both to YYYY-MM-DD, and the verifier is where
you discover the third case.
A tech-crawler.contract/verify-all pass reports per-source
\{:name :status :count :conformance :error\} (and summary rolls those up).
That report is the measurement hook for C-001 (per-source normalize failures) and
C-004 (selector/parse match counts): the conjectures stop being slogans and
become a table you can refute.
A representative clean pass over the live registry (Walsh-Research/1.2, 61 live
sources):
{:sources 61, :ok 56, :error 5, :empty 1, :nonconforming 0, :clean 55}
The headline is :nonconforming 0: every source that parses, conforms. The
single normalize path handles 100% of the variance it actually sees, so C-001
holds with room to spare. The work is entirely at the edges, and the verifier
hands you the exact locus:
- Apple ML Research —
ParseError [45,67]: a bare&in a title (Machine Learning & AI). Fixed by a sanitize-bare-ampersand pass beforexml/parse-str, which left the 51 healthy feeds untouched. Recovered. - Logic Magazine —
ParseError [116,151]: the feed URL serves a Netlify "page not found" HTML page, not a feed. Dead; demoted with a reason. - Dan Luu —
ParseError [37423,90]: malformed deep in a 37k-line archive, and not a bare-&case. Demoted pending a closer look. - Netflix Tech Blog / James Bornholt — TLS-chain and connection failures. Host-side and transient; left in place to re-check.
- harvard-seas — 200 with zero items (the Localist API returned no events).
Two of those five were diagnosed and resolved in minutes precisely because the loop was a REPL, not a log-and-rerun cycle (see the case study below).
The crawl pipeline
// Crawl pipeline: gate -> fetch -> parse -> normalize -> dedup -> store digraph crawl_pipeline { rankdir=LR; graph [bgcolor="white", fontname="Helvetica", fontsize=11, pad="0.3", nodesep="0.35", ranksep="0.5"]; node [shape=box, style="rounded,filled", fontname="Helvetica", fontsize=10]; edge [color="#888888", fontname="Helvetica", fontsize=9]; source [label="source URL", fillcolor="#dbeafe", color="#1d4ed8", fontcolor="#1d4ed8"]; subgraph cluster_gate { label="pre-request gate"; style="rounded"; color="#b91c1c"; fontcolor="#b91c1c"; fontsize=11; r3 [label="blocklist (R3)", fillcolor="#fee2e2", color="#b91c1c", fontcolor="#b91c1c"]; r2 [label="robots RFC 9309 (R2)", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; r4 [label="throttle (R4)", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; } fetch [label="fetch\n(R5 backoff,\nR7 conditional)", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; cache [label="validator cache\n(ETag / 304)", fillcolor="#fef9c3", color="#a16207", fontcolor="#a16207"]; adapter [label="adapter\n(feed/json/md)", fillcolor="#ede9fe", color="#6b21a8", fontcolor="#6b21a8"]; normalize [label="normalize\n{:title :url :source\n :date :tags}", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; dedup [label="dedup\n(canonical URL)", fillcolor="#fef3c7", color="#b45309", fontcolor="#b45309"]; store [label="EDN append log", fillcolor="#dcfce7", color="#15803d", fontcolor="#15803d"]; source -> r3; r3 -> r2; r2 -> r4; r4 -> fetch; cache -> fetch [style=dashed]; fetch -> cache [style=dashed, label="store validators"]; fetch -> adapter; adapter -> normalize; normalize -> dedup; dedup -> store; }

Conditional fetch (If-None-Match / If-Modified-Since) turns most runs into a
wall of 304 Not Modified, which is the point: a daily crawl should be cheap and
quiet. Dedup is by canonical URL (coerce/canonical-url drops the #fragment
and any trailing slash), so re-runs accumulate first-seen items only.
Politeness is the hard part
Flight tracking reads paid, read-only APIs. Crawling reads other people's
sites, which makes compliance the load-bearing wall, not an afterthought.
tech-crawler implements the published Walsh-Research compliance contract
(walsh-research-compliance/v1.2): full RFC 9309 robots matching (Allow +
*=/=$ wildcards, longest-match), a self-describing operator blocklist, backoff
with Retry-After, and a versioned identity, Walsh-Research/1.2.
The gate from the pipeline above is the same gate the contract specifies, in the same order (operator opt-out before robots before pacing):
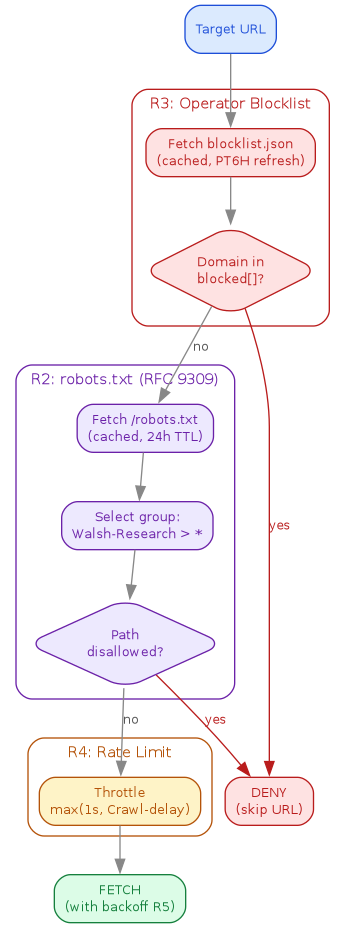
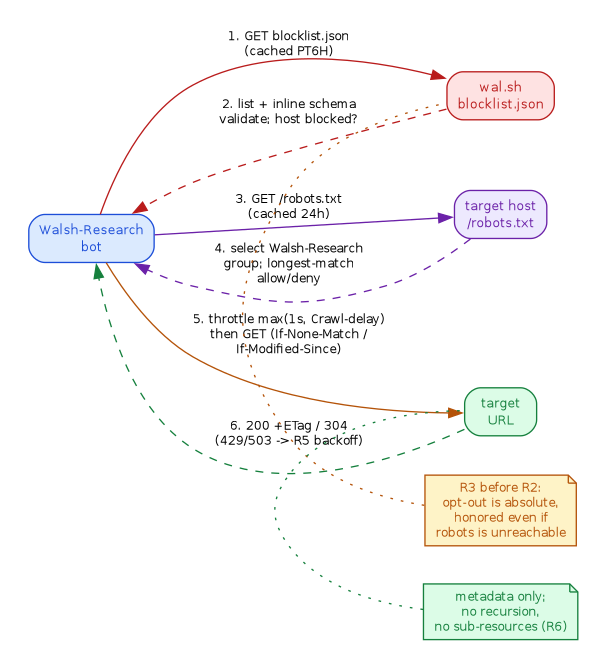
We dogfood it against our own site: three canary pages under /research/bots/
exercise both directions of the robots gate, and dogfood-walsh-only doubles as
a honeypot — since * is disallowed there and only Walsh-Research is
allowed, any other agent in the access logs is a robots-violating bot.
Case studies
From HTML scrape to RSS (Hacker News, arXiv)
Both started as enlive scrapes of a rendered page. Each browser redesign broke a
selector; neither carried reliable dates. Moving HN to /rss and arXiv to
rss.arxiv.org deleted the selector-maintenance surface and gained real
pubDate. This is conjecture C-004 (selector stability) resolving the only way
it cleanly can: stop depending on selectors.
Parse-error triage at the REPL (Apple ML, Dan Luu, Logic Magazine)
Three feeds fail to parse. The REPL is the whole debugger: (def body (crawler/fetch
url)), hand body to clojure.data.xml, and read exactly where it throws —
a malformed entity reference near row 116 for Logic Magazine, a large Atom feed
choking near row 37423 for Dan Luu. No log line added, no re-run loop. The verdict
(repair the adapter vs demote the feed with a recorded reason) is a one-line edit
once you can see the failure. This is the workflow tc-contract-verifier turns
into verify-all.
Content negotiation: markdown first
For feed-less sources the crawler sends Accept: text/markdown and uses the body
only when the server answers with a markdown content-type, falling back to HTML
otherwise; it also probes /llms.txt. From any markdown body it extracts links
generically ([text](url), absolute, de-duplicated, in order) — no per-site
structure, which keeps it on the right side of the no-scraping rule.
Feed health as falsification
Dead and hostile feeds are recorded, not silently dropped: transformer-circuits
returns 403 to all clients, Anthropic dropped RSS entirely. Both are demoted to
:planned with a reason string, which is itself a C-004 signal. A coverage crawl
is a falsification run for the source registry.
Agentic REPL harness
The same harness as the flight-tracking work (bead tc-harness): a long-lived
JVM nREPL daemon holds the crawler and its loaded namespaces; a Babashka client
speaks bencode to it, so an agent issues hundreds of probes at ~100ms each
instead of paying ~2.5s of JVM startup per clj -M. The loop is
hypothesis-driven and stateful:
# 1. observe a source's shape ./probe '(keys (first (feed/parse (crawler/fetch "https://.../feed.xml"))))' # 2. sample the date formats in play ./probe '(->> (feed/parse body) (map :date) frequencies)' # 3. bind the erroring sources for the session ./probe '(def broken (->> (contract/verify-all) (filter :error)))' # 4. refine ./probe '(map (juxt :name :error) broken)'
Each evaluation builds on the last; the daemon keeps body and broken around
for the whole session. That persistence is the difference between a REPL and a
script.
Open conjectures
This crawler is run as a falsification engine (CPRR). The standing claims:
- C-001 — one
normalizehandles >80% of source variance. Refuted if more than three sources need bespoke post-normalize fixups. (Measured byverify-all.) - C-002 — daily frequency suffices. Refuted if items appear and vanish inside 24h. (Measured by first-seen timestamps.)
- C-003 — title+url+date+source+tags suffices for triage. (User study, deferred.)
- C-004 — adapters stay stable quarter to quarter. Refuted by any feed that breaks within 30 days; the RSS migration and the demotion log are the running record.
Resources
- tech-crawler — the Clojure crawler this is drawn from
- Walsh-Research compliance spec (
v1.2) and the bot policy - REPL-Driven Flight Tracking — the sibling piece
- Babashka — fast Clojure scripting for the nREPL client
- Expert Clojure Workflows for AI Agents — the four-skill framing this mirrors
- nrepl-bencode experience — the Babashka nREPL client skill